Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Costruisco sistemi di AI che gestiscono le tue operazioni di business
Livello 2
Ha soddisfatto criteri di prestazioni elevate e ha una comprovata esperienza nel soddisfare le aspettative dei clienti.
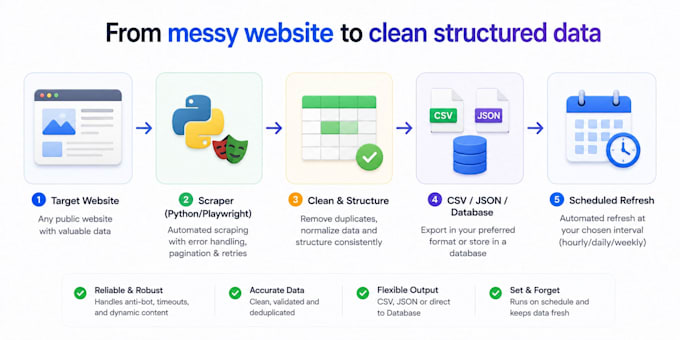
Hai bisogno di dati da un sito web ma copiarli a mano ti fa perdere troppo tempo? Creo scraper in Python e bot di automazione browser che estraggono dati puliti e strutturati in modo automatico.
Ciò che realizzo:
Strumenti: Python, Scrapy, BeautifulSoup, Playwright, Selenium, Requests, curl_cffi, Pandas, servizi proxy (Bright Data, ScraperAPI, ZenRows).
Consegno codice pronto all’uso con istruzioni chiare, così puoi eseguirlo di nuovo in qualsiasi momento, più 7 giorni di correzioni gratuite.
Contattami con il sito target e i campi di cui hai bisogno.

Tecnologia:
Python
•
scrapy
•
selenium
•
Beautiful soup
•
Playwright
Tecnica:
Automatizzato
Traduzione automatica.
È legale / conforme?
Seguo i ToS del sito, robots.txt e le leggi sulla privacy. Non raccolgo dati sensibili o bypasso paywall. Solo dati pubblici/aziendali.
Puoi gestire siti dinamici, scroll infinito o pagine renderizzate con JS?
Sì, usando Playwright/Selenium/Scrapy con paginazione, scrolling, condizioni di attesa e resilienza ai cambiamenti di layout.
Di cosa hai bisogno per iniziare?
URL del sito, campi da estrarre, pagina/i di esempio, volume previsto, formato di output (CSV/Excel/JSON/Sheets/DB) e eventuali credenziali di login/test se richiesto.
Cosa succede con captcha, limiti di rate o blocchi?
Utilizzo proxy rotanti, user-agent, backoff/ripetizioni e throttling intelligente. Se ci sono anti-bot pesanti, proporrò alternative sicure o copertura parziale.
Quali formati potete fornire?
CSV, Excel, JSON, Google Sheets o caricamento diretto su SQLite/PostgreSQL/MySQL. Posso anche fornire uno schema ETL semplice e pronto.
Includi pulizia dati e validazione?
Sì, deduplicazione, trimming, casting, regex parsing e controlli di completezza/unicità dove applicabile.
Ottengo solo lo script di scraping o anche i dati?
Consegna dati di base/standard. La versione Premium include codice Python + guida all'installazione. La proprietà dello script passa a te.
Puoi impostare scraping programmato / monitoraggio?
Sì, esecuzioni giornaliere/settimanalmente con aggiornamenti via email/Sheets. La versione Premium può includere deployment Dockerizzato o un scheduler cloud leggero.
Puoi estrarre dati da qualsiasi sito io voglia?
Posso fare scraping della maggior parte dei siti web accessibili pubblicamente. Alcuni siti hanno termini di servizio rigidi o richiedono login per dati privati, che segnalerò prima di iniziare. Scrape solo dati pubblicamente disponibili e rispetto i limiti legali. Inviami l’URL target e confermerò la fattibilità prima che tu ordini.