Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Bangladesh
Su di me
Stai cercando di costruire un modello di self-supervised learning (SSL) e scoprire cluster significativi nei tuoi dati?
- Sei nel posto giusto! Sono un esperto di Deep Learning con esperienza pratica in SSL, clustering e valutazione di task downstream.
Posso lavorare con vari dataset di immagini, tra cui:
Perché scegliere il mio servizio?
Cosa consegno:
Facciamo vivere i tuoi dati! Contattami prima di ordinare per assicurarti che i requisiti del progetto siano pienamente compresi.



Expertise:
Elaborazione immagini
•
Classificazione
•
clustering
Linguaggio di programmazione:
Python
•
Colab
•
Altro
Strumenti:
Quaderno jupyter
•
opencv
•
Colab
•
PyTorch
Framework:
PyTorch
•
Panda
•
Altro
Traduzione automatica.
Con che tipi di dataset puoi lavorare?
Posso lavorare con qualsiasi tipo di dataset di immagini, comprese immagini mediche, immagini satellitari, immagini di prodotti o dataset personali/personalizzati.
Devo fornire un set di dati?
Sì. se vuoi che il modello venga addestrato sui tuoi dati (prodotti, volti, documenti, ecc.), devi fornire le immagini. Se non hai un dataset, posso aiutarti a raccoglierne o trovarne uno a pagamento. Scrivimi prima!
Ho bisogno di dati etichettati?
No, il self-supervised learning non richiede dati etichettati. Tuttavia, le etichette potrebbero essere necessarie se vuoi una valutazione su un task downstream (pacchetti Standard & Premium).
Ci sono limiti sulla dimensione del dataset?
Di solito lavoro con dataset che rientrano nella memoria GPU disponibile, come Colab e Kaggle GPU. Per dataset molto grandi, possiamo usare strategie come sampling, batching o elaborazione distribuita.
Quali modelli di deep learning usi?
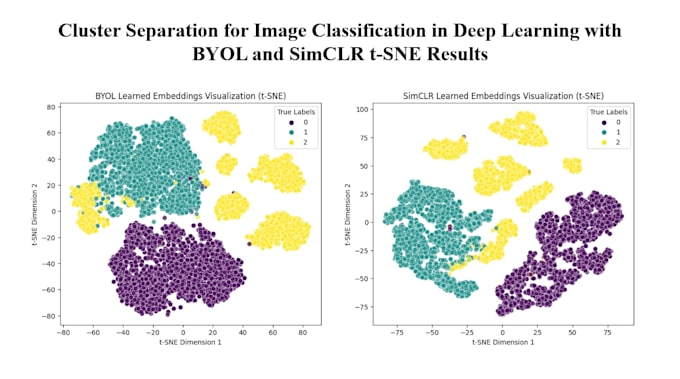
Utilizzo modelli di Self Supervised Learning all’avanguardia come SimCLR, BYOL, Barlow Twins.
Potrò usare facilmente il modello?
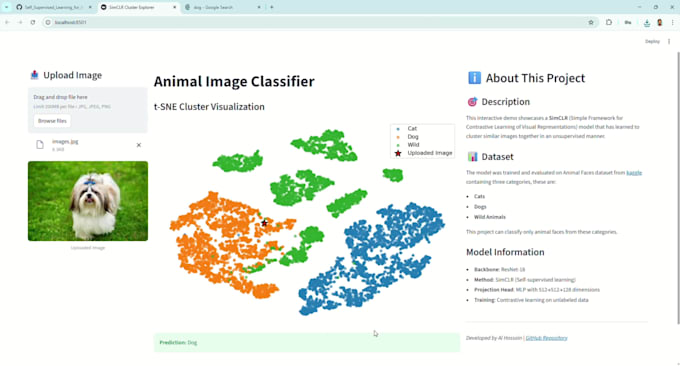
Sì! Per il pacchetto Premium, fornisco una web app Streamlit facile da usare per esplorare interattivamente i cluster e testare i task downstream.
Puoi valutare le prestazioni del modello?
Sì, fornisco metriche di valutazione dettagliate sui task downstream, tra cui accuratezza, perdita e visualizzazioni dei cluster.
Garantite la riservatezza?
Sì, completamente. I tuoi dati e i dettagli del progetto sono mantenuti strettamente riservati.