Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Automazione, web scraping Django, Flask, sviluppo frontend InstagramAnalyst
Livello 1
Ha soddisfatto determinati criteri di prestazione e mostra un forte potenziale nel marketplace.
Ciao,
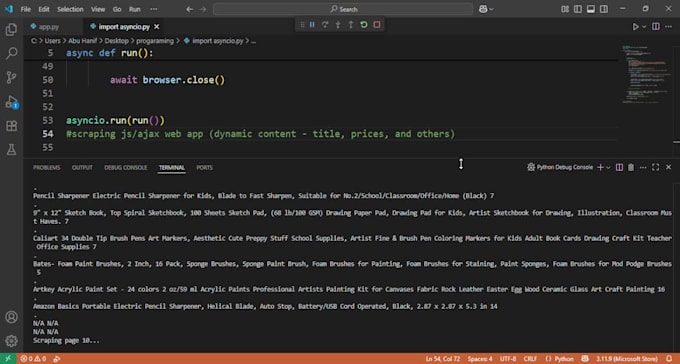
Hai bisogno di estrarre dati da un sito web in modo rapido e pulito? Creo web scraper personalizzati in Python usando BeautifulSoup, Selenium, Playwright e Scrapy per un'estrazione accurata e automatizzata di dati da qualsiasi sito pubblico.
Offro servizi di web scraping e estrazione dati di livello esperto utilizzando strumenti di settore come:
️ Strumenti di scraping che utilizzo:
Caratteristiche & Output:
Scrape solo fonti di dati pubbliche e legalmente accessibili.
Contattami prima di ordinare per discutere il tuo caso d'uso. Sono pronto ad aiutarti a automatizzare e estrarre i dati web di cui hai bisogno.
almohid

Tecnologia:
Python
Tecnica:
Automatizzato
Traduzione automatica.
Cos'è il web scraping e come può beneficiare la mia attività?
Il web scraping è l'estrazione automatizzata di dati dai siti web. Permette alle aziende di raccogliere dati preziosi e strutturati per ricerche di mercato, analisi della concorrenza, monitoraggio dei prezzi, generazione di lead, aggregazione di dati di prodotto e tracciamento delle tendenze, tutto senza sforzo manuale.
Quali tipi di siti web puoi scrapeare con Python?
Scrapeo una vasta gamma di siti, tra cui negozi di e-commerce, portali di lavoro, annunci immobiliari, directory di aziende locali, portali di notizie, database accademici e altro ancora. *Nota: verifica sempre le autorizzazioni del sito prima di procedere con lo scraping.
Puoi scrapeare siti che usano JavaScript pesante o caricamenti dinamici?
Assolutamente! Usando Playwright e Selenium, gestisco pagine web complesse con contenuti dinamici caricati tramite AJAX, scroll infinito o altri elementi JavaScript, assicurando che nessun dato venga perso.
Come gestisci siti che richiedono login o autenticazione di sessione?
Automatizzo processi di login sicuri usando Playwright o Selenium, gestendo cookie e token di sessione per estrarre dati dietro le mura di login, nel pieno rispetto dei termini e condizioni del sito.
In quali formati posso ricevere i dati estratti?
Consegno dati puliti e validati in formati come CSV, Excel, JSON, XML, database SQL o Google Sheets, adattandoli alle tue preferenze di workflow o alle esigenze di integrazione del sistema.
Fornisci gli script di scraping e il codice di automazione?
Sì! Su richiesta, condivido script Python completamente commentati e riutilizzabili, costruiti con Playwright, Selenium o Scrapy, che ti permettono di eseguire o personalizzare lo scraper in modo autonomo.
Puoi configurare lavori di scraping programmati e automatizzati?
Certamente. Configuro cron jobs, funzioni cloud o scraper senza server per eseguirli automaticamente a intervalli personalizzati — quotidianamente, settimanalmente o mensilmente — per un aggiornamento continuo dei dati.
Come gestisci le protezioni anti-scraping e il rilevamento di bot?
Implemento tecniche avanzate tra cui rotazione user-agent, uso di proxy, modalità stealth del browser (specialmente con Playwright), throttling delle richieste e gestione CAPTCHA (dove consentito) per bypassare eticamente le misure anti-bot più comuni.
Quanto tempo ci vorrà per ricevere i miei dati estratti?
Il tempo di consegna dipende dalla complessità: compiti di scraping semplici di solito richiedono 1-3 giorni; progetti di crawling multi-pagina o di grandi dimensioni richiedono 3-7 giorni. Fornisco tempi chiari e trasparenti prima di iniziare.