Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Data Engineer, AWS, Apache Airflow, Spark, PostgreSQL, ETL
Are you drowning in raw data with no reliable way to process it?
I build production-grade data pipelines that run automatically, scale with your data, and never break silently. No spaghetti scripts. No manual steps. Just clean, reliable data exactly where you need it.
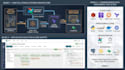
What I Build

Q: What information do you need to get started?
A: Your data source (S3, API, database, CSV), your target destination, transformation requirements, and how often the pipeline should run.
Q: Can you work with my existing infrastructure?
A: Yes. Send me details and I will assess compatibility before we start.
Q: Do I need an AWS account?
A: For AWS-based work yes — you will need your own account. I can guide you through the setup if needed.
Q: Will I own the code?
A: Completely. All source code is handed over to you on delivery.
Q: Can you handle large datasets?
A: Yes. I use PySpark and EMR on EKS specifically because they are built for large-scale data processing.
Q: What if something breaks after delivery?
A: I offer post-delivery support. Message me and I will fix it.


