Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
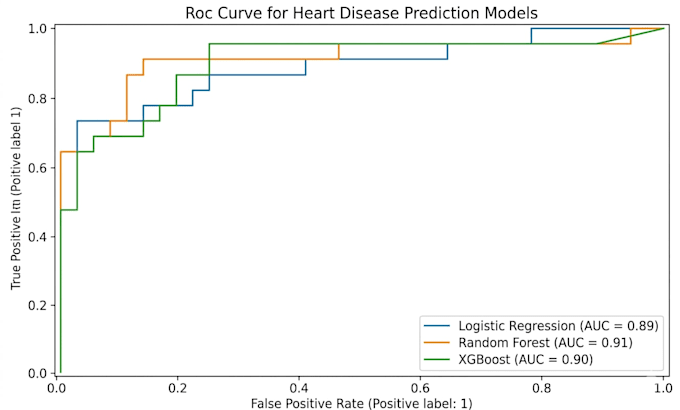
Data Scientist
Trasforma i tuoi dati in uno strumento potente per le decisioni con un Data Scientist certificato IBM.
Non scrivo solo codice; costruisco modelli di Machine Learning ad alte prestazioni pensati per precisione e affidabilità. Con un background in Ingegneria e formazione specializzata da IBM, colmo il divario tra dati grezzi complessi e intuizioni aziendali o cliniche azionabili.
Ciò che otterrai:
Perché scegliermi? Applico un mentalità ingegneristica alla data science, concentrandomi su precisione, stabilità del modello e performance nel mondo reale. Che si tratti di dati sanitari, finanziari o aziendali, consegno risultati di cui puoi fidarti.
Pronto a sbloccare il potere dei tuoi dati?



Linguaggio di programmazione:
Python
•
SQL
Framework:
Scikit-learn
•
Panda
API:
Visione artificiale Microsoft AI
Strumenti:
Quaderno jupyter
•
MLflow
Traduzione automatica.
Di cosa hai bisogno da me per iniziare?
Ho bisogno del tuo dataset (CSV, Excel, SQL o accesso API) e di una descrizione chiara del tuo obiettivo. Stai cercando di prevedere un risultato specifico o hai bisogno solo di un'analisi esplorativa? Più contesto fornisci sulle feature, migliori saranno i risultati.
Quali strumenti e librerie usi?
Lavoro principalmente in Python usando lo stack standard del settore: Pandas e NumPy per la gestione dei dati, Matplotlib e Seaborn per le visualizzazioni, e Scikit-Learn, XGBoost o LightGBM per il Machine Learning. Tutto il lavoro viene consegnato in Jupyter Notebooks organizzati.
Puoi garantire una precisione specifica del modello?
Nella data science, la precisione dipende interamente dalla qualità e dalla quantità dei tuoi dati. Tuttavia, garantisco un approccio rigoroso di Ingegneria—usando GridSearchCV e Cross-Validation—per assicurarci di trovare il modello con le migliori prestazioni possibile per il tuo dataset specifico.
Riuscirò a capire e far funzionare il codice da solo?
Assolutamente. Fornisco codice pulito e commentato che segue le migliori pratiche. I miei pacchetti Standard e Premium includono anche un rapporto tecnico professionale (PDF) che spiega metodologia e risultati in modo semplice, così puoi presentare i risultati a stakeholder non tecnici.
Puoi lavorare con dati sensibili o medici?
Sì. Con il mio background in Ingegneria Biomedica, sono molto consapevole dell'importanza della privacy dei dati e dell'accuratezza clinica. Seguo un'etica professionale rigorosa per garantire che i tuoi dati rimangano confidenziali e sicuri durante tutto il processo.