Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Su questo servizio
Sono specializzato nella creazione di sistemi multimodali di riconoscimento vocale ed emozionale combinando modalità audio e testo per migliorare prestazioni e precisione.
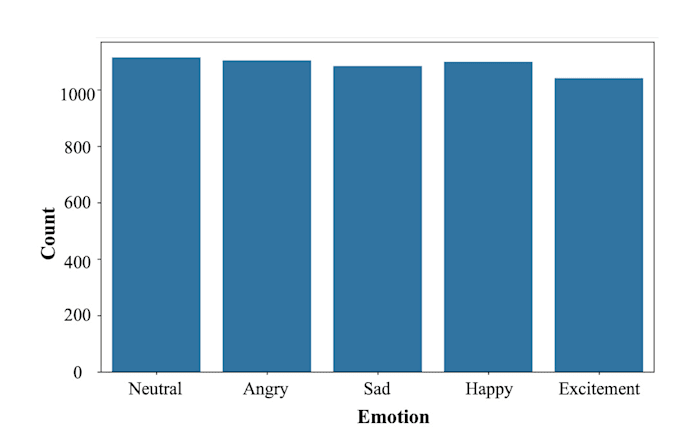
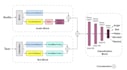
Con esperienza pratica su dataset complessi come IEMOCAP e MELD, ho sviluppato modelli ibridi personalizzati usando Bi-LSTM e CNN, raggiungendo fino al 85% di accuratezza sul dataset IEMOCAP. Sto anche esplorando attivamente Word2Vec e architetture basate su Transformer per migliorare la comprensione contestuale nel riconoscimento vocale.
Puoi consultare i miei progetti e articoli di ricerca linkati qui sotto per maggiori dettagli.
Cosa offro:
Sentiti libero di scrivermi prima di ordinare per discutere le tue esigenze specifiche.

Expertise:
Classificazione
•
Discorso e audio
•
Analisi predittiva
Linguaggio di programmazione:
Python
•
Colab
API:
Altro
Strumenti:
Quaderno jupyter
•
Amazon SageMaker
•
Colab
Framework:
Scikit-learn
•
keras
•
PyTorch
•
Panda
•
tensorflow