Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD

Traduzione automatica.
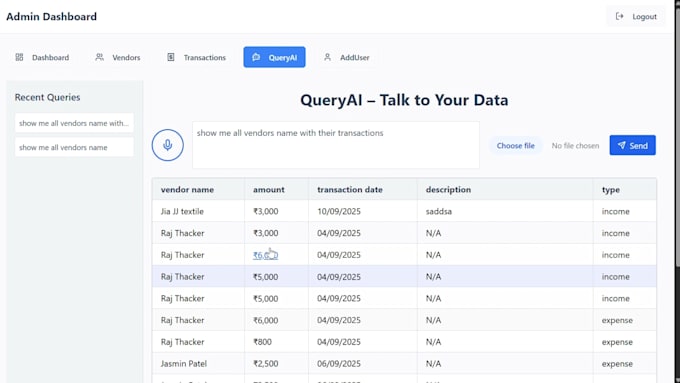
Hai bisogno di automatizzare l'estrazione di informazioni dai documenti invece di fare copia e incolla manualmente? Creo soluzioni di automazione basate su Python che elaborano i file rapidamente, con precisione e su larga scala.
Ho esperienza nella creazione di workflow di elaborazione documenti per report finanziari, gestione delle fatture, automazione dei fogli di lavoro e pipeline di dati strutturati.
Ciò che posso aiutarti a fare:
Estrazione di dati da fatture, ricevute, moduli e documenti finanziari
Elaborazione di tabelle e informazioni strutturate da file complessi
Gestione di documenti multi-pagina e file scansionati usando OCR
Conversione delle informazioni estratte in JSON, CSV, Excel o formati pronti per database
Creazione di script di automazione o workflow basati su API per integrazione nei sistemi esistenti
Piattaforma tecnologica: Python · pdfplumber · PyMuPDF · OCR · FastAPI · SQL
I deliverable includono codice pulito, istruzioni di configurazione, documentazione e esempi di output per i test.
Per favore, inviami un messaggio con un file di esempio e il formato di output desiderato prima di ordinare, così posso confermare l'ambito e la fattibilità.
Python Backend Developer with FastAPI REST APIs and AI Integration
Lingue
Traduzione automatica.
Traduzione automatica.
Puoi gestire i PDF scansionati?
Sì, utilizzo OCR (Tesseract/AWS Textract) per documenti scansionati.
In quale formato sarà l'output?
JSON, CSV o direttamente nel tuo database — a tua scelta.
Puoi processare automaticamente i PDF secondo una pianificazione?
Sì, posso creare una pipeline automatizzata con il pacchetto Standard o Premium.