Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD



Traduzione automatica.
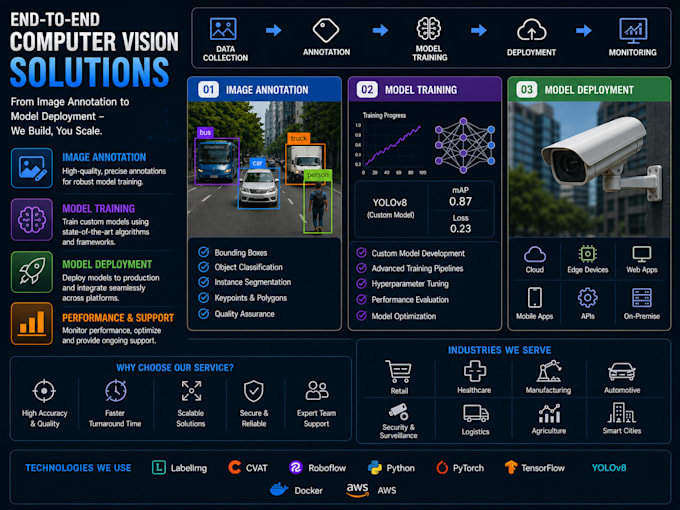
Annoto le tue immagini e addestro un modello YOLO personalizzato che rileva I TUOI oggetti, non demo pre-addestrate generiche.
Sono membro di NVIDIA Inception con un team di AI/ML in Python che ha implementato sistemi di rilevamento oggetti in produzione in ambito manifatturiero, sicurezza, ristorazione e analisi sportive in 6 paesi.
COSA CONSEGNO:
PASSO 1 ANNOTAZIONE & ETICHETTATURA
Annotazione con bounding box, poligono o keypoint
Strumenti: CVAT, LabelImg, Roboflow, Label Studio, esportazione in formato YOLO (yaml + etichette txt)
PASSO 2 PREPARAZIONE DEL SET DI DATI
Augmentation, suddivisione train/val/test, controllo qualità
PASSO 3 ADDESTAMENTO DEL MODELLO YOLO
Training personalizzato YOLOv8 sul tuo dataset, accelerato da GPU su NVIDIA CUDA, report mAP, precisione, recall e matrice di confusione
PASSO 4 DEPLOYMENT (solo Premium)
Ottimizzazione TensorRT, inferenza 3-5x più veloce, endpoint di inferenza FastAPI, script Python pronto all’uso
COSA HO CREATO:
Tracking di 22 giocatori di calcio contemporaneamente
Rilevamento di fumo e PPE su hardware NVIDIA Jetson
Monitoraggio della conformità alle norme igieniche in cucina
Ricevi: dataset etichettato, pesi del modello addestrato, script di inferenza e report di training.
Contattami prima di ordinare con le tue immagini e il caso d’uso.
AI App Development Expert, Computer Vision, OpenCV, Object Detection
Lingue
Traduzione automatica.
Traduzione automatica.
Quali formati di immagine accetti?
JPG, PNG, BMP, TIFF e frame video da MP4. Posso estrarre frame dal tuo video se necessario.
E se non ho ancora dati etichettati?
Nessun problema. L’annotazione è il primo passo. Invia le immagini raw e descrivi quale oggetto vuoi rilevare.
Quante immagini servono per una buona precisione?
Almeno 200 per classe per una rilevazione di base. Oltre 500 per classe portano a un mAP tra 85 e 92%. Oltre 1000 arrivano al 90-96%.
Puoi lavorare con immagini mediche o satellitari?
Sì. Invia prima un esempio di immagine e confermerò la fattibilità prima di procedere con l’ordine.
Puoi distribuire sul mio server invece che su Jetson?
Sì. Distribuisco tramite FastAPI su AWS, Google Cloud o qualsiasi server Linux con supporto GPU.