Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Ingegnere del software
Ingegneria Big Data professionale per infrastrutture scalabili e pronte per la produzione
Offro soluzioni pratiche end-to-end di big data, dalla pianificazione dell'architettura fino al deployment e all'ottimizzazione, utilizzando strumenti standard del settore. Ogni soluzione è personalizzata in base ai tuoi obiettivi, all'infrastruttura e ai requisiti di workload per garantire prestazioni, scalabilità e stabilità a lungo termine.
Servizi inclusi:
Perché i clienti scelgono questo servizio:


Lingua:
Inglese
•
Urdu
Esperienza tecnica:
Apache NiFi
•
Apache Spark
•
hadoop
•
Altro
Settore:
Analisi dei dati
Traduzione automatica.
Che tipi di progetti di big data gestisci?
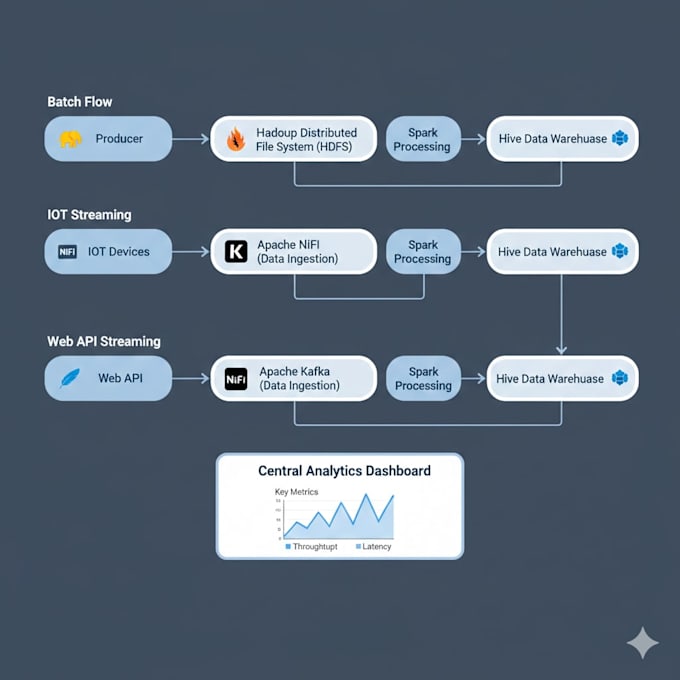
Mi occupo di configurazione, deployment, ottimizzazione e troubleshooting di ambienti big data usando Hadoop, Spark, Kafka, Hive, NiFi e strumenti correlati — da sistemi di prova di piccole dimensioni a cluster di produzione.
Puoi configurare un cluster completo di Hadoop o Spark da zero?
Sì. Posso progettare e deployare cluster completamente funzionanti, inclusa la configurazione, l'ottimizzazione delle prestazioni e la validazione per garantire stabilità.
Supporti pipeline di streaming di dati in tempo reale?
Assolutamente. Costruisco pipeline di streaming basate su Kafka e le integro con Spark o NiFi per un'elaborazione efficiente dei dati in tempo reale.
Fornite documentazione?
Sì. È inclusa una documentazione chiara per aiutarti a capire, gestire e mantenere il sistema.
Come cominciamo?
Basta condividere i tuoi requisiti, i dettagli dell'infrastruttura e gli obiettivi — ti proporrò il miglior piano di implementazione.