Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD





Traduzione automatica.
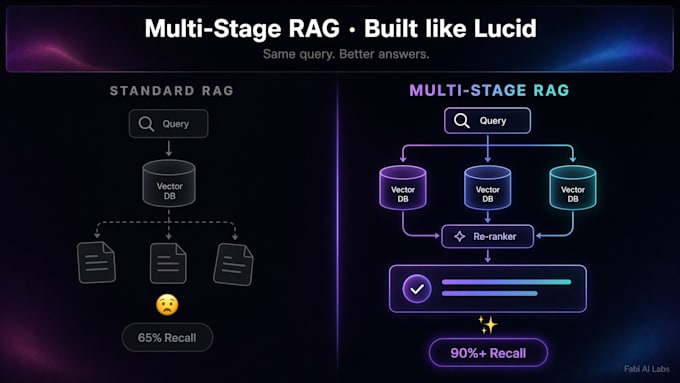
Il RAG standard si blocca di fronte a domande composte. Un bot che risponde a una sola query recupera pezzi che menzionano "rimborso" e perde le sfumature - regole di prezzo, clausole di danno, politiche di ordini personalizzati.
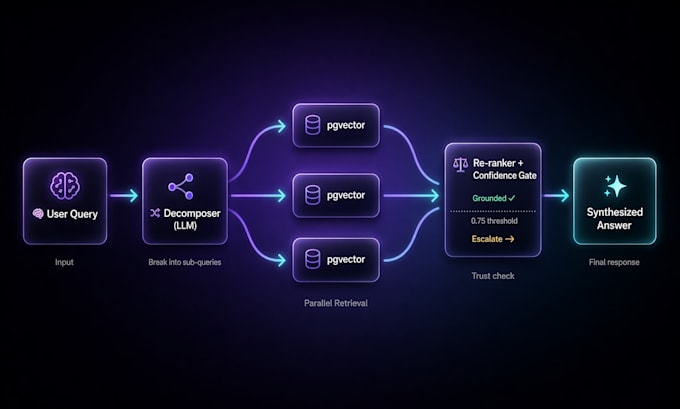
Il RAG multi-stage è diverso. Si decomprime in sotto-query, recupera in parallelo, ri-rank e sintetizza. La recall salta dal 65% al 90%+. Le risposte restano ancorate. Le hallucination diminuiscono.
COSA OTTIENI:
- Decomposizione delle query (LLM suddivide domande complesse in ricerche mirate)
- HyDE ipotetico embedding di documenti per il retrieval
- Ri-rank + punteggio di fiducia prima della generazione della risposta
- 4 salvaguardie: passaggio umano, porta dell'incertezza, niente gaslighting, trasparenza
- Set di test di valutazione personalizzato con qualità di retrieval misurabile
- Dashboard di amministrazione per debug di conversazioni + retrieval (Premium)
STACK: Python/TypeScript, Supabase pgvector, API di OpenAI/Anthropic/Gemini, re-ranker personalizzato.
PERCHÉ MULTI-STAGE: il RAG a query singola funziona per FAQ semplici. Se il tuo bot gestisce sfumature di prezzo o domande composte - hai bisogno di questo.
Questo è ciò che ho integrato in Lucid. Stessa architettura per il tuo dominio, adattata alla tua voce.
Inviami il tuo caso d'uso più 10 domande difficili a cui il tuo attuale bot non riesce a rispondere. Risponderò con il scope.
AI Developer and Creator of Lucid
Lingue
Traduzione automatica.
Traduzione automatica.
Come si differenzia il multi-stage RAG dal RAG di base?
Il RAG di base esegue una ricerca vettoriale per domanda. Per domande composte, la recall a ricerca singola è circa il 65%. Il multi-stage RAG decomprime la domanda, cerca in parallelo, ri-rank. La recall salta al 90%+. Meno hallucination, risposte più ancorate.
Questo costerà più del RAG di base su larga scala?
Spesso meno. La decomposizione utilizza modelli economici (Gemini Flash a circa 0,10$ per 1M token). La risposta finale usa una chiamata premium. Il RAG di base paga premium per ogni chiamata. Con oltre 10k conversazioni al mese, il multi-stage è spesso dal 30 al 50% più economico.
E se i miei documenti sono disordinati o non strutturati?
Gestito come parte del scope. Normalizzo i documenti durante l'ingestione - chunking per confini semantici (non suddivisioni naive in paragrafi), pulizia di boilerplate, aggiunta di metadata per retrieval basato su filtri. Input disordinato è l'ipotesi di default, non un'eccezione.
Devo comunque portare le mie API keys?
Sì - stessa politica del mio gig Starter Bot. Possiedi gli account di OpenAI / Anthropic / Gemini, paghi direttamente senza markup, mantieni il controllo completo. Ti aiuto a scegliere il mix di modelli più conveniente per il volume del traffico.