Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD


Traduzione automatica.
Stop a spendere soldi per chiamate AI ridondanti!
La maggior parte delle app AI spreca dal 40% all'80% del budget in chiamate ridondanti a LLM. Sono qui per aiutarti a fermare questa perdita.
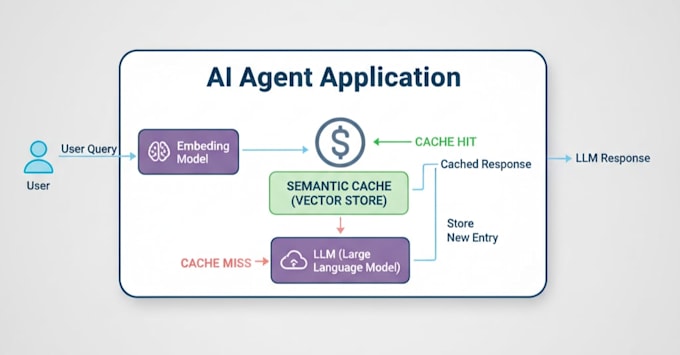
Costruirò un Cache Semantica pronta per la produzione che "ricorda" le query passate e fornisce risposte istantanee, riducendo i tuoi costi e rendendo la tua app velocissima.
Cos'è il caching semantico?
Il caching standard è "stupido": richiede una corrispondenza parola per parola al 100%. Il caching semantico è intelligente. Usando Vector Embeddings, il tuo sistema comprenderà l'intento. Se l'utente A chiede "Come va il tempo?" e l'utente B chiede "Previsioni del tempo?", il sistema sa che sono la stessa cosa. Fornisce subito la risposta memorizzata senza chiamare la tua API.
️ Cosa include questo servizio?
Code, Scrape, Automate, FullStack Developer for Data and AI
Lingue
Traduzione automatica.
Traduzione automatica.
La cache farà sì che l'AI dia informazioni "vecchie" o "sbagliate"?
Non se viene fatta correttamente. Implementiamo "Invalidazione della cache" e impostazioni di "Time-to-Live" (TTL). Se i tuoi dati cambiano frequentemente, possiamo impostare la cache per scadere ogni ora. Se sono dati statici, può durare per sempre. Tuning anche la "Soglia di somiglianza" in modo che solo le domande veramente simili attivino la cache.
Quanto risparmierò realmente?
Dipende dal tuo "tasso di hit della cache". Per bot di supporto clienti o FAQ, gli utenti fanno spesso domande simili, portando a risparmi tra il 60% e il 90%. Per bot altamente creativi o con richieste uniche, i risparmi sono di solito tra il 20% e il 30%.
I miei dati sono al sicuro?
Assolutamente sì. La cache è ospitata sulla tua infrastruttura (o sul tuo cloud preferito). Non memorizzo i tuoi dati sui miei server.
Funziona con qualsiasi LLM?
Sì. Che tu usi GPT-4o di OpenAI, Google Gemini 1.5, Claude 3.5, o modelli locali come Llama 3, il layer di caching si trova davanti all'API, rendendolo indipendente dal provider.