Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
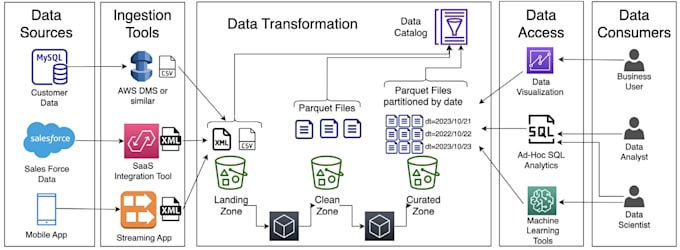
Senior Data Engineer, Spark, Scala, AWS, Airflow, Kafka, Big Data
Stai cercando un PySpark Data Engineer affidabile per costruire o ottimizzare i tuoi pipeline ETL?
Sei nel posto giusto.
Sono Pankaj, un Data Engineer con oltre 3 anni di esperienza in Paytm, dove ho realizzato più di 200 pipeline ETL in produzione che elaborano oltre 5 TB/giorno usando PySpark, Airflow, AWS e Kafka.
Questo servizio si concentra al 100% sulla consegna di soluzioni PySpark ETL rapide, scalabili e pulite per il tuo business.
Cosa posso fare per te
Perché scegliermi
Tecnologie che utilizzo
Hai bisogno di qualcosa di personalizzato?
Scrivimi in qualsiasi momento, rispondo rapidamente.
Costruiamo qualcosa di scalabile.

Traduzione automatica.
Cosa ti serve da me per iniziare?
Accesso a database/API, dati di esempio, logica SQL o descrizione del problema.
Puoi connetterti al mio database o API?
Sì — MySQL, PostgreSQL, MongoDB, API, S3 e altro ancora.
Ottimizzi pipeline esistenti?
Sì — Sono specializzato in ottimizzazione runtime e debugging.
Puoi integrare i servizi AWS?
Sì — Glue, S3, EMR, Lambda, Athena.
Puoi firmare un accordo di non divulgazione?
Sì — Posso lavorare sotto NDA se necessario.