Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
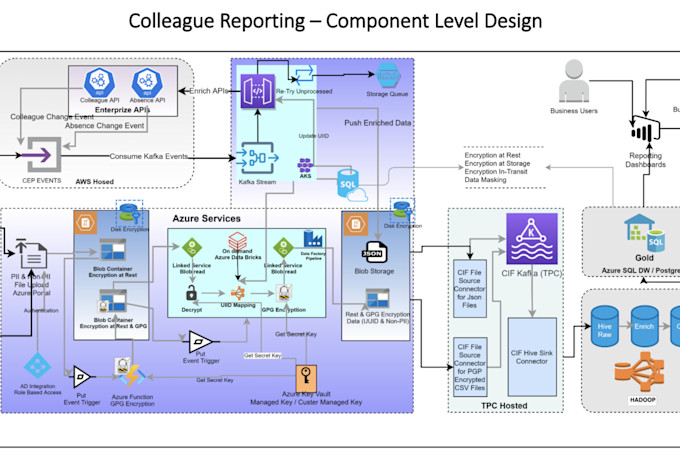
Senior Data Engineer: AWS, Azure, Spark, pipeline ETL e architettura dei dati
Hai problemi con pipeline di dati lente o inaffidabili? Progetto e costruisco pipeline ETL di livello produzione su AWS e Azure che sono veloci, scalabili e fatte per durare.
Ciò che otterrai:
- Progettazione e implementazione end-to-end di pipeline ETL
- Ottimizzazione delle performance di Apache Spark (PySpark, Scala)
- Configurazione AWS: Glue, Lambda, Step Functions, S3, Redshift
- Configurazione Azure: Databricks, Data Factory, Azure Data Lake Gen2
- Validazione dei dati, gestione degli errori e monitoraggio
- Documentazione completa e consegna
Ideale per:
- Aziende con pipeline di dati lente o che falliscono
- Team che migrano da on-prem a AWS o Azure
- Progetti che necessitano di ottimizzazione e tuning di Spark
- Sviluppo di ETL in tempo reale o batch
Perché scegliere me:
Oltre 5 anni di esperienza nella creazione di pipeline di dati aziendali nei settori retail, IoT e finanza. Ho gestito pipeline che elaborano milioni di record ogni giorno e porterò la stessa competenza nel tuo progetto.



Destination Platform:
Amazon Redshift
•
Amazon S3
Strumenti e piattaforme:
AWS Glue DataBrew