Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD

Senior Tech Lead Data Engineering
Competenze
Consulta i miei servizi

Senior Tech Lead — Data Engineering
Falabella Colombia • Full time
Apr 2024 - Present • 2 yrs 3 mos
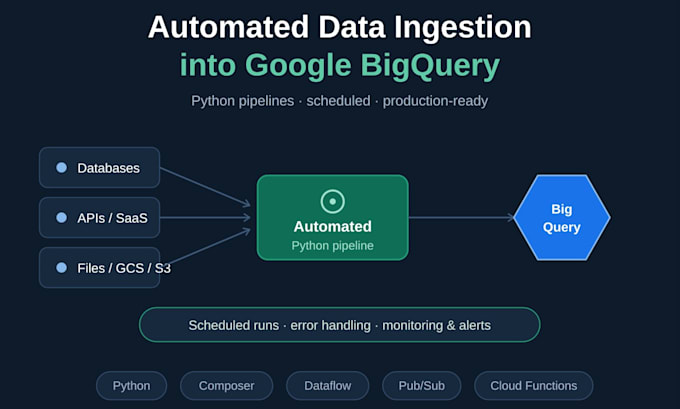
As Senior Tech Lead and Lead Data Engineer at Falabella India, I architected the product feed system, resolving data discrepancies for ~1M products. Built seller-facing tools including a recommendation engine, analytics dashboard (GMV, NMV, clicks, conversion), and GenAI chatbot for performance queries. Implemented product-matching using embeddings and cosine similarity for competitive analysis. Optimized GCP infrastructure, reducing costs while improving reliability. Established federated BigQuery-PostgreSQL pipelines ingesting ~200 tables across orders, catalog, and promotions domains. Built data quality and observability frameworks ensuring SLA adherence. Led cross-functional teams translating business requirements into scalable technical solutions.
Lead Data Engineer | Tata Cliq
Tata Group • Full time
Oct 2022 - Jan 2024 • 1 yr 3 mos
Led data platform optimization and quality initiatives for e-commerce marketplace. Spearheaded datalake cost optimization on AWS, achieving ~40% monthly cost reduction through process and job optimization. Built in-house Data Quality Check (DQC) framework using AWS Deequ, deployed on EMR with Airflow orchestration and Athena for querying. Implemented sentiment analysis pipeline using GPT-3.5 API processing product reviews and customer feedback, deployed in production on AWS EMR. Automated DQC and sentiment analysis job scheduling using Apache Airflow, ensuring reliable and timely execution.
Technical Lead- Big Data | Cigna
Cigna • Full time
Sep 2018 - Nov 2022 • 4 yrs 2 mos
Architected and operationalized healthcare insurance data products at scale using Spark and Scala. Developed complex healthcare insurance models, collaborating with business analysts to translate requirements into technical solutions. Designed and built Rule Management system enabling self-serve analytics for stakeholders. Integrated Apache Drools with Apache Spark, executing rules defined in DMN format for dynamic policy evaluations. Migrated legacy Hive models to Spark Scala, improving performance and maintainability. Engineered Kafka-based jobs for publishing downstream insights to analytical platforms. Led team development efforts with expertise in TDD and CI/CD pipeline implementation. Managed change requests and supported production models across healthcare domain.
