Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD




Traduzione automatica.
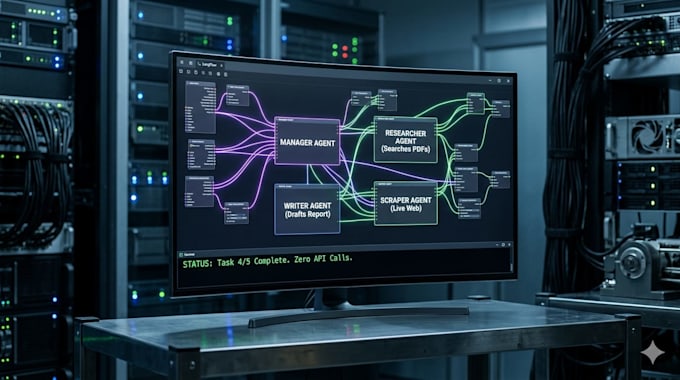
Costruisco Infrastrutture AI Sovrane sistemi privati, locali e ad alte prestazioni che girano sul tuo hardware con Zero costi API.
Come Systems Architect, mi specializzo nel deploy di Large Language Models (LLMs) e agent autonomi che danno priorità a Sovranità dei Dati e Privacy. Che tu abbia bisogno di un assistente di ricerca privato o di un workflow multi-agent complesso, consegno codice pulito, pronto per la produzione e ottimizzato per l'esecuzione locale.
Ciò che Offro:
Il Deliverable: Ogni progetto include Codice Sorgente, un ambiente Dockerizzato per setup con un clic e documentazione professionale. Nessun gatekeeping, possiedi il sistema che costruisco.
Stop ai pagamenti per token. Costruisci la tua fortezza.
Local Intelligence, Total Privacy, Expert AI Solutions
Lingue
Traduzione automatica.
Traduzione automatica.
cos'è esattamente "Sovereign Ai" e perché ne ho bisogno?
Sovereign AI significa possedere la propria intelligenza invece di affittarla. Costruisco sistemi che girano sul tuo hardware o cloud privato. Nessun dato lascia la tua rete, e non paghi costi mensili API. È il controllo totale sui tuoi dati e sul tuo futuro digitale.
Ho bisogno di un server da 10.000$ per far girare LLM locali?
No. Usando quantizzazione (GGUF/EXL2), ottimizzo modelli come Llama 3 per funzionare su hardware consumer. Una RTX 3060/4060/5060 con 8GB VRAM è più che sufficiente per un assistente privato ad alta velocità. Mi specializzo nel far funzionare modelli "pesanti" su macchine snelle ed efficienti.
L'AI può leggere in modo sicuro i miei documenti aziendali privati?
Sì. Uso RAG (Retrieval-Augmented Generation) per creare un "Vector Database" locale. L'AI cerca nei tuoi PDF, CSV o file SQL in tempo reale. I tuoi dati non toccano mai internet e non vengono usati per addestrare modelli pubblici. Rimangono al 100% privati.
Qual è la differenza tra RAG e Fine-Tuning?
RAG è come un "esame a libro aperto"—l'AI cerca fatti nei tuoi dati. Il Fine-tuning è "chirurgia cerebrale"—cambia la personalità o il gergo specializzato dell'AI. RAG è migliore per l'accuratezza; il Fine-tuning per una voce unica. Offro entrambi per garantire sinergia totale del sistema.
È più economico rispetto a pagare per ChatGPT Plus o API?
A lungo termine, assolutamente. Anche se c'è un costo iniziale, il tuo costo per messaggio diventa 0,00$. Per aziende con alto volume, una configurazione sovrana si ripaga in 3-6 mesi eliminando trappole di abbonamento ricorrente e lock-in con i fornitori.
Come consegnate il prodotto finale?
Fornisco un "Sovereign Container" via Docker. Niente installazioni complesse o problemi con i driver. Ottieni uno script di setup con un clic e un README professionale. Esegui lo script e l'AI si avvia nel browser come app web privata e sicura.
Mi aiuterai con la configurazione iniziale?
Ogni pacchetto include una guida dettagliata. Per le fasce Standard e Premium, offro una sessione remota 1-a-1 per ottimizzare l'ambiente in base alla tua GPU e VRAM, assicurandoti le massime prestazioni di tokens-per-second possibili.