Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
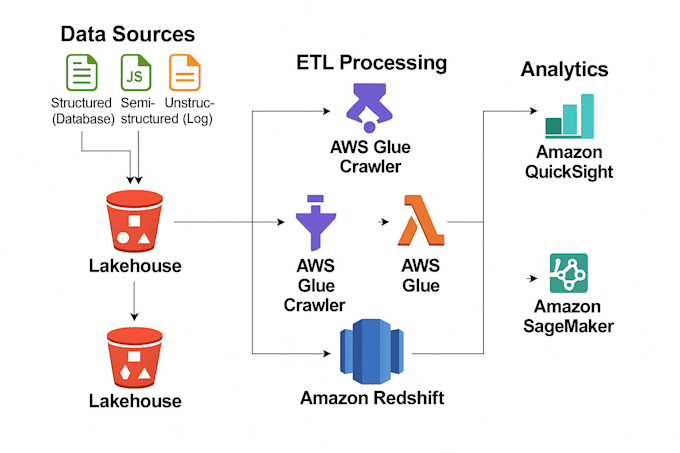
Progetto e costruisco pipeline di dati scalabili su misura per le esigenze della tua azienda. Usando Python, PySpark, SQL e AWS, automatizzo l'ingestione, la trasformazione e l'archiviazione dei dati per fornire dati puliti, affidabili e pronti per l'analisi. Eseguo controlli sulla qualità dei dati come il rilevamento di valori mancanti, rimozione di duplicati, verifica del formato e convalida dello schema per garantire l'integrità dei dati.
Creo anche dashboard interattivi e report con Amazon QuickSight e Tableau per aiutarti a monitorare i KPI e prendere decisioni basate sui dati facilmente. Che tu abbia bisogno di workflow ETL, convalida dei dati, deployment nel cloud o soluzioni di reporting, consegno sistemi ottimizzati e scalabili.
Metto al primo posto una comunicazione chiara, consegne puntuali e supporto continuo per far evolvere la tua infrastruttura di dati insieme al tuo business. Trasformiamo i tuoi dati grezzi in insight utili!
Expertise:
Big data
•
Convalida dati
•
etl
•
Trasformazione
•
QA
•
SQL