Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Ingegnere dei dati cloud, BigQuery, Snowflake, dbt, Python, ETL
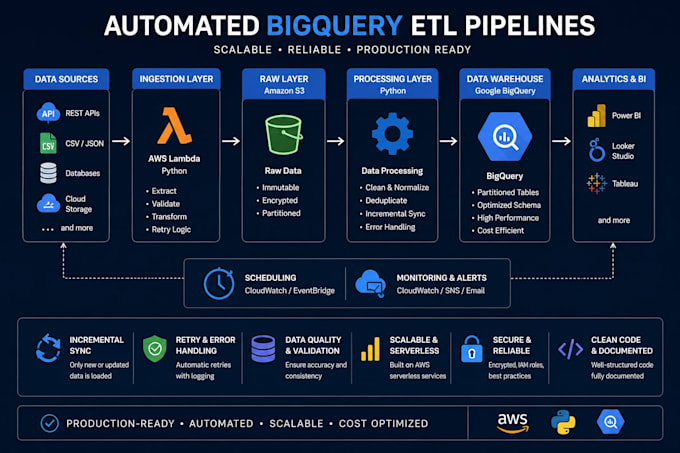
Crea una pipeline ETL scalabile e pronta per la produzione, partendo da API, CSV, JSON, database o storage cloud direttamente in Google BigQuery.
Sono specializzato in pipeline di dati automatizzate basate su Python per analisi, report, Power BI, Looker Studio, Tableau e piattaforme di business intelligence.
I servizi includono:
Ingestione API BigQuery
Caricamento incrementale dei dati
Backfill storico
Normalizzazione JSON / CSV
Pipeline automatizzate programmate
AWS Lambda / architettura serverless
Gestione di retry & error
Logging & monitoraggio
Deduplicazione dei dati
Tabelle BigQuery partizionate
Architettura Raw Staging Curated
Strutture di magazzino dbt-ready
Tecnologie:
- Python
- BigQuery
- AWS Lambda
- S3 / GCS
- Airflow / Prefect
- dbt
- REST APIs
Casi d'uso tipici:
- Analisi e-commerce
- Report finanziari
- Dashboard di marketing
- Integrazioni CRM
- Sistemi di report automatizzati
Mi concentro su architetture scalabili, manutenibili e pronte per la produzione, piuttosto che su semplici script.
Contattami prima di ordinare per progetti personalizzati o di grandi dimensioni.
Le revisioni non includono cambiamenti di scope principali o integrazioni aggiuntive.





Traduzione automatica.
Supporti grandi dataset?
Sì. Progetto pipeline scalabili per milioni di record e carichi di lavoro di produzione.
Puoi distribuire su AWS?
Sì. Posso implementare architetture serverless usando Lambda, S3, Step Functions e CloudWatch.
Puoi ottimizzare i costi di BigQuery?
Sì. Uso partizionamento, clustering, elaborazione incrementale e pattern di query ottimizzati.
Quale architettura preferisci per la pipeline di dati?
Posso costruire la pipeline usando architetture native AWS o GCP, a seconda della tua infrastruttura esistente, budget e requisiti di reporting. 1. API → Cloud Run / Cloud Function → GCS Raw → BigQuery 2. API → Lambda → S3 Raw → BigQuery Data Transfer Service → BigQuery
Puoi costruire pipeline ETL incrementali?
Sì. Preferisco fortemente l'elaborazione incrementale rispetto ai ricarichi completi per scalabilità, costi ridotti di BigQuery e affidabilità migliorata.
Supporti le trasformazioni dbt?
Sì. Posso creare modelli dbt per staging, pulizia, join, logica di business e tabelle di analisi curate.
Puoi lavorare con data warehouse o pipeline esistenti?
Sì. Posso migliorare, ottimizzare, debug o estendere ambienti BigQuery, AWS o ETL esistenti.
Puoi integrare Power BI o altri strumenti BI?
Sì. Posso preparare dataset pronti per analisi ottimizzati per Power BI, Looker Studio, Tableau e analisi SQL.
Fornisci monitoraggio e gestione errori?
Sì. Le pipeline di produzione includono logging, retries, alert e monitoraggio per migliorare affidabilità e stabilità operativa.
Puoi gestire backfill storici e grandi dataset API?
Sì. Posso costruire pipeline per sincronizzazione storica, API paginati e dataset di grandi dimensioni con strategie di caricamento ottimizzate.