Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Architetto dell'automazione dei dati e specialista ETL
Infrastruttura dati & Analytics
Costruisco sistemi ETL/ELT che trasformano dati frammentati in risorse affidabili. Focus: stabilità e scalabilità piuttosto che soluzioni temporanee.
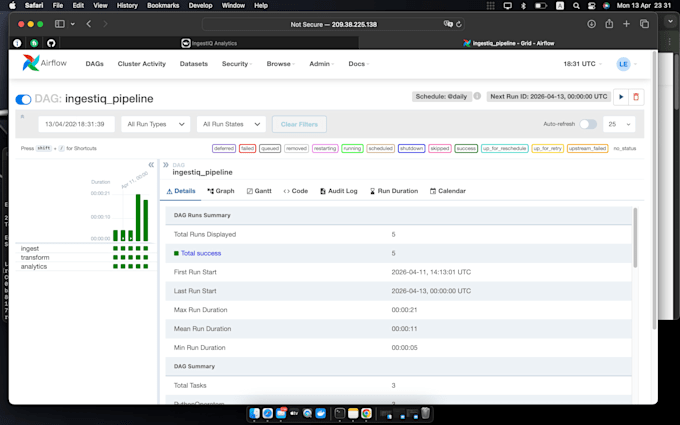
Perché questa architettura funziona:
Design modulare: pipeline scollegate dalle fonti per una scalabilità sicura.
Strato di coerenza: validazione e gestione dello stato per una precisione del 100%.
Storage Bronze/Silver: livelli raw/processed per ottimizzare le prestazioni.
Deployment agnostico: soluzioni Docker per qualsiasi cloud o setup on-premise.
Dashboard personalizzate: interfaccia Streamlit inclusa in ogni progetto.
Collaborazione & confini: consegno sistemi autonomi con limiti chiari:
Scope: copre fonti e deployment definiti. Logica e integrazioni nuove sono iterazioni separate.
Affidabilità: gestione proattiva degli errori inclusa. monitoraggio 24/7 o manutenzione server sono servizi separati.
Ownership: documentazione fornita per la manutenzione autonoma.
Stack: Python, SQL, Airflow, Docker, Postgres, DuckDB.
Contattami prima di ordinare per allinearti sui requisiti!

Destination Platform:
PostgreSQL
•
MySQL
•
Altro
Strumenti e piattaforme:
Altro