Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
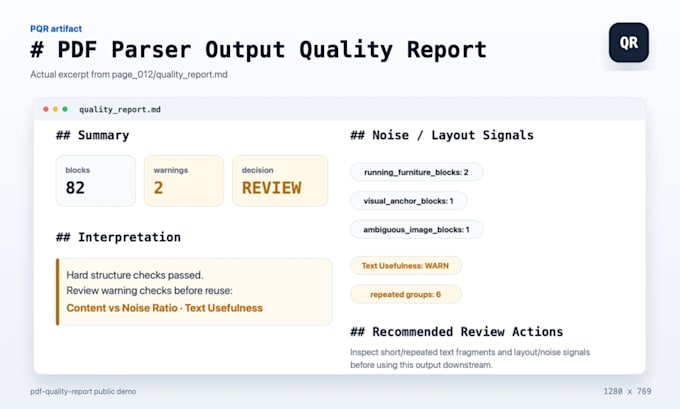
Revisione output PDF in JSON e Markdown
Il risultato dell'estrazione del tuo PDF sembra utilizzabile, ma ha bisogno di essere pulito e verificato prima di revisione, pulizia, mappatura dello schema o preparazione all'ingestione RAG?
Revisiono l'output dei parser esistenti da Docling, PyMuPDF, Unstructured o strumenti simili e creo:
Il lavoro parte dal tuo obiettivo: quali campi sono importanti, quali ID o riferimenti di origine devono essere preservati e come utilizzerai l'output a valle.
Ciò di cui ho bisogno:
Ciò che non coprirò:

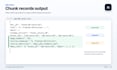
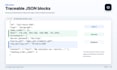
Tecnologia:
Python
Traduzione automatica.
Con quali formati di parser puoi lavorare?
Il JSON di Docling è il più adatto. Anche output di parser come PyMuPDF, Unstructured, LlamaParse o simili in formato JSON/dict possono funzionare dopo una verifica rapida.
Fornisci servizi di OCR o ricostruzione di tabelle?
Non di default. Questo servizio riguarda la revisione e la pulizia dell'output del parser esistente. Documenti scansionati, pulizia OCR e ricostruzione di tabelle complesse richiedono un scope personalizzato dopo una verifica di esempio.
È questa una costruzione di sistema RAG?
No. Posso preparare record JSON, Markdown o JSONL revisionabili per la preparazione all'ingestione, ma non costruisco il chatbot, il sistema di retrieval, il database vettoriale o la valutazione della qualità delle risposte.