Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
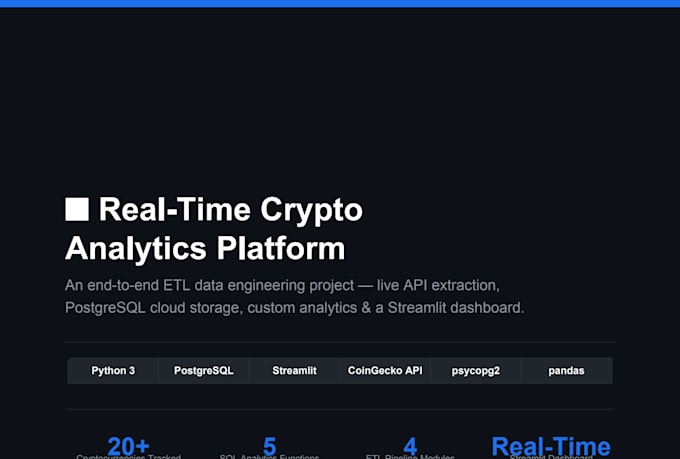
Trasformo i dati in intelligenza usando machine learning e deep learning
Cerchi modelli ML precisi, pronti per la produzione, che risolvano problemi reali? Sei nel posto giusto.
Costruisco soluzioni end-to-end di machine learning e deep learning in Python, partendo da dati grezzi e disordinati fino a modelli predittivi completamente funzionanti e pipeline di dati.
COSA OTTIENI
PROGETTI REALI CONSEGNATI
Codice pulito. Spiegazioni chiare. Risultati reali.
Contattami prima di ordinare, discutiamo del tuo progetto!

Linguaggio di programmazione:
Python
•
SQL
Framework:
Scikit-learn
•
keras
API:
Altro
Strumenti:
Quaderno jupyter
•
tensorflow
•
Excel
•
MLflow
•
Colab
Traduzione automatica.
Che tipo di problemi di ML puoi risolvere?
Posso risolvere un'ampia gamma di problemi di ML supervisionato e non supervisionato, tra cui regressione (previsione prezzi, previsione vendite), classificazione (rilevamento spam, churn, ecc.), clustering e rilevamento anomalie. Se non sei sicuro che il tuo problema rientri, scrivimi e te lo dirò.
Devo fornire il mio set di dati?
Sì, idealmente dovresti fornire il tuo dataset. Tuttavia, se non ne hai uno, posso reperire un dataset pubblico rilevante (da Kaggle, UCI o API aperte) per il tuo problema. Più i dati sono buoni, migliore sarà l'accuratezza del modello — quindi condividere dati reali dà sempre i migliori risultati.
In quale formato saranno consegnati i prodotti?
Riceverai un Jupyter Notebook (.ipynb) pulito con codice sorgente completo, spiegazioni commentate e visualizzazioni. Per i pacchetti Standard e Premium, riceverai anche un rapporto PDF o una documentazione del modello. Tutti i file sono consegnati come archivio ZIP, così tutto è organizzato e pronto all'uso.
Puoi garantire una precisione specifica del modello?
Nessun professionista ML onesto può garantire un'accuratezza fissa, dipende molto dalla qualità, dalla dimensione dei dati e dalla complessità del problema. Quello che garantisco è che applicherò le migliori tecniche di preprocessing, feature engineering e ottimizzazione del modello per massimizzare le prestazioni. Ti mostrerò sempre le metriche di valutazione.
Quali librerie e strumenti Python usi?
Principalmente uso scikit-learn, Pandas, NumPy, Matplotlib e Seaborn per ML e analisi dei dati. Per pipeline e database uso PostgreSQL, psycopg2 e MySQL. Per dashboard uso Streamlit. Per compiti di deep learning uso TensorFlow/Keras. Tutte le librerie sono standard del settore e ampiamente supportate.
Capirò il codice anche se non sono tecnico?
Assolutamente sì. Ogni notebook è scritto con commenti chiari, passo dopo passo, che spiegano cosa fa ogni blocco di codice e perché. Per i pacchetti Standard e Premium, includo anche un riassunto scritto dei risultati e delle scoperte in inglese semplice, così capisci le intuizioni, non solo il codice.
Puoi distribuire il modello così posso usarlo in diretta?
Sì, la distribuzione cloud e l'integrazione API sono incluse nel pacchetto Premium. Posso distribuire il tuo modello come app web Streamlit o endpoint API REST, così è pronto all'uso in produzione. Se hai bisogno di deployment su piattaforme specifiche (AWS, Render), scrivimi prima di ordinare per allinearci sulla configurazione.
E se ho bisogno di qualcosa di personalizzato non elencato nei tuoi pacchetti?
Nessun problema. Scrivimi con le tue esigenze e ti invierò un'offerta personalizzata su misura per te. Che si tratti di un dataset unico, un algoritmo specifico, una pipeline più grande o un progetto combinato ML + dashboard. Sono felice di discutere e quotare di conseguenza.
I miei dati vengono mantenuti riservati?
Al 100% sì. I tuoi dati vengono usati esclusivamente per completare il tuo progetto e non vengono mai condivisi, pubblicati o riutilizzati in alcun modo. Se hai bisogno di un Non-Disclosure Agreement (NDA) prima di condividere dati sensibili, sono disponibile a firmarne uno. La tua privacy e sicurezza dei dati sono prese molto sul serio in ogni progetto.
Come funzionano le revisioni?
Basic include 1 revisione, Standard 2, Premium 3. Una revisione copre aggiustamenti all'ambito esistente come modificare parametri del modello, cambiare visualizzazioni o correggere bug. Non include l'aggiunta di nuove funzionalità o algoritmi oltre l'ambito concordato.