Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Crea applicazioni web intelligenti con AI e soluzioni NLP per i dati
Titolo: Organizzazione automatica di documenti & analisi NLP
Ciao! Se sei sopraffatto da un enorme mucchio di documenti PDF, posso aiutarti a organizzarli usando NLP alimentato dall'AI.
Non mi limito a raggruppare i file per parole chiave di base. Utilizzo embedding semantici avanzati per capire il vero significato del tuo testo, assicurando che i tuoi documenti siano categorizzati in modo logico e preciso.
Cosa offro:
Mi concentro su precisione e codice pulito. Scrivimi oggi per discutere del tuo progetto!




Linguaggio di programmazione:
Python
Framework:
Scikit-learn
•
Panda
Strumenti:
Quaderno jupyter
•
Colab
Traduzione automatica.
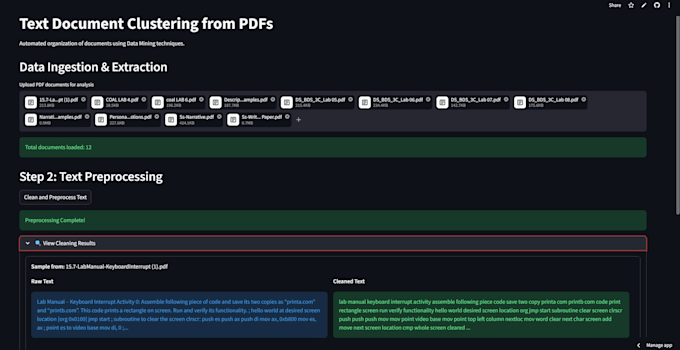
Che tipo di documenti PDF puoi processare?
Posso processare quasi tutti i PDF basati su testo, inclusi articoli di ricerca, report aziendali e articoli.
Puoi processare anche file Microsoft Word (.docx)?
Sì, assolutamente! Sebbene la versione standard del mio strumento sia ottimizzata per i PDF, posso facilmente modificare il pipeline di ingestione dati per gestire file .docx e .doc.
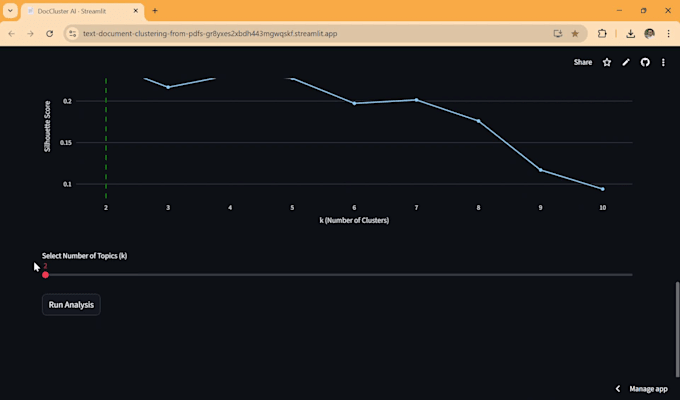
Come garantisci che i cluster siano accurati?
Utilizzo un'analisi "Silhouette Score" per determinare matematicamente il numero più logico di gruppi per i tuoi dati. Questo assicura che i cluster non siano solo casuali, ma basati su una densità semantica reale.
Devo fornire gli "Argomenti" in anticipo?
No! Si tratta di "Learning non supervisionato," cioè l'AI identifica i pattern e raggruppa i documenti da solo.
I miei dati sono al sicuro?
Assolutamente. Elaboro i tuoi dati localmente nel mio ambiente di sviluppo sicuro. Una volta consegnato e accettato il progetto, elimino i tuoi documenti dal mio sistema a meno che tu non richieda diversamente.
Posso eseguire il dashboard Streamlit sul mio computer?
Sì. Se scegli il pacchetto Premium, fornisco un file requirements.txt e una configurazione .devcontainer, rendendo facile eseguire l'app localmente in VS Code o distribuirla nel cloud.