Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD

Intelligent Document Processing, Offline Advanced PDF Process, AI, ML
Competenze
Consulta i miei servizi
Self Employed
Lavoratore autonomo • 1 yr 11 mos
Data Annotation - Image , text , Audio
Dec 2025 - Present • 7 mos
We do Image annotation for object detection and instance segmentation . We have done annotation for around 25k images using offline tool
Advanced PDF Data Extarction and processing
Nov 2025 - Present • 8 mos
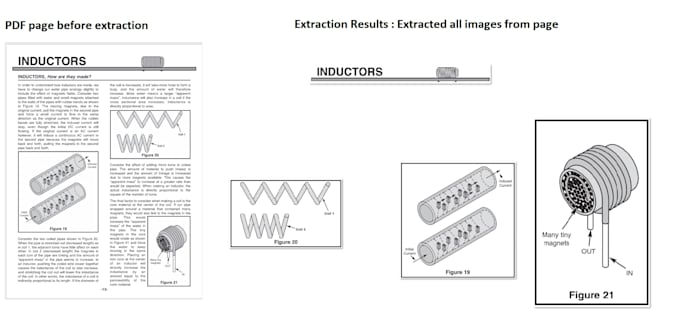
High-Fidelity Diagram & Asset Extraction: We isolate and extract inline vectors, technical block diagrams, medical illustrations from almost all PDFs like scientific, mechanical, aerospace, Newspaper, text books, scanned books, any reports like research, historical sketches, also from complex documents into crisp image files, which can be fed to AI for your training, it can be used in PPTs, research or recovering old files in library. Samples are available in portfolio Extract Labels from images into JSON or text file or desired format Local PDF Manipulation (Alternative to online processing): Our own build tool does following actions *Dynamically delete PDF pages *Merge multiple documents Compress large size into small pdfs, *Split large PDFs based on exact page counts or file size limits— all processed locally. Page-to-Image Rendering: High-resolution conversion of individual PDF pages into standalone images.
Extraction, Transformation, Loading (ETL) , Testing
Nov 2025 - Present • 8 mos
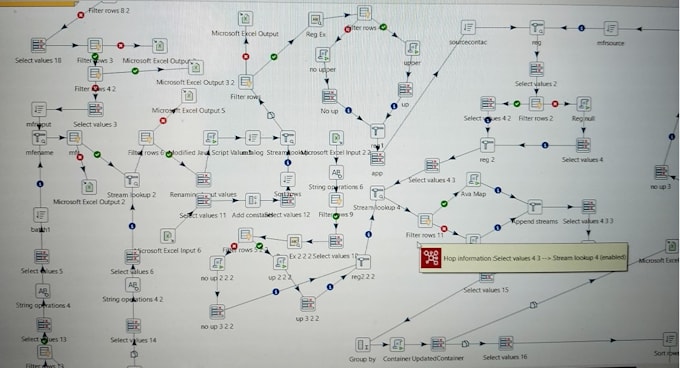
We do processing of huge volume of data , Data cleansing, Data extraction , Data mapping according to desired rules or format, Data transformation , Data Loading, Data migration , Testing. If required we will also provide data in preferable format ( for database loading) Below is the sample flow Data Extraction: Extract the raw flat file (e.g., CSV, TXT, Excel) from the source system. Data Transformation: Data Cleansing & Deduplication example Eliminate duplicate records, handle missing values, and filter corrupt data before any processing begins. Data Mapping: Map the source file fields to the corresponding target system attributes or change the source values according to requirement. Business Logic & Type Conversion: Apply business logic, format strings, and convert data types (e.g., casting text to integers, standardizing date formats like YYYY-MM-DD). Data Loading Generate target file and save the processed data into the desired output format.
