Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Farò scienza dei dati o analisi dei dati
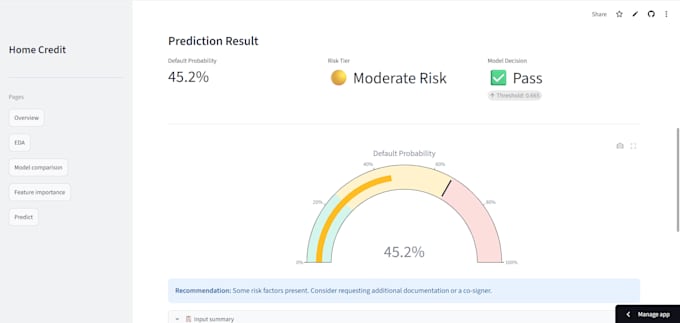
Demo dal vivo: credit-risk-prediction-better.streamlit.app
GitHub: github.com/Niqar/Credit-risk-prediction
Hai dati grezzi ma non sai come trasformarli in un modello ML funzionante? Ti costruirò una pipeline di machine learning completa, pronta per la produzione, dal dato disordinato a un modello che funziona davvero.
Cosa consegnerò:
Pulizia dei dati e feature engineering (gestione dei valori mancanti, encoding, scaling)
Training del modello con LightGBM, XGBoost, Random Forest o Logistic Regression
Ottimizzazione degli iperparametri con Optuna per le migliori prestazioni
Relazione di valutazione completa (AUC, F1-score, Precision, Recall, Confusion Matrix)
Pipeline di scikit-learn pulita, riproducibile e pronta per essere deployata
Jupyter Notebook + codice Python documentato
Repository GitHub (su richiesta)
Perché lavorare con me:
Non mi limito a addestrare un modello e consegnarlo. Documenterò ogni passaggio così capirai cosa è stato fatto e perché, e mi assicurerò che la pipeline sia abbastanza pulita da poter essere riutilizzata o estesa.
Guarda il mio portfolio: credit-risk-prediction-better.streamlit.app
Senti libero di scrivermi prima di ordinare, così posso rivedere il tuo dataset e confermare che posso aiutarti.



Linguaggio di programmazione:
Python
•
SQL
Framework:
Scikit-learn
•
keras
•
PyTorch
Strumenti:
Quaderno jupyter
•
opencv
•
tensorflow
•
Excel
•
Colab
Traduzione automatica.
Con che tipo di dati lavori?
Lavoro con dati strutturati/tabulari — CSV, Excel o esportazioni SQL. Questo copre problemi di classificazione ( frode, churn, rischio di credito) e di regressione (previsione dei prezzi, forecast delle vendite). Per dati di immagini o testo, contattami prima così posso valutare l'ambito.
Cosa succede se il mio dataset è disordinato o ha valori mancanti?
È del tutto normale — gestire dati disordinati fa parte di quello che faccio. Li pulisco, gestisco i valori mancanti, encodo le caratteristiche categoriche e scala quelle numeriche come parte di ogni pacchetto.
Quali modelli di apprendimento automatico utilizzi?
Principalmente LightGBM, XGBoost, Random Forest e Logistic Regression — a seconda dei tuoi dati e obiettivi. Nei pacchetti Standard e Premium addestro e confronto più modelli per offrirti quello con le migliori prestazioni.
Potrò riutilizzare o modificare il codice da solo?
Sì. Tutto il codice è pulito, commentato e strutturato come una pipeline scikit-learn vera e propria — così puoi riaddestrarlo con nuovi dati o modificare i parametri facilmente. Spiegherò anche le parti chiave, così non resterai nel dubbio.