Servizi professionali di Data Engineering | Pipeline ETL | AWS | Databricks
Stai cercando di creare pipeline di dati scalabili e affidabili per la tua attività?
Sono un Data Engineer con oltre 6 anni di esperienza nella progettazione e ottimizzazione di pipeline ETL usando tecnologie cloud e big data moderne.
Ciò che posso fare per te:
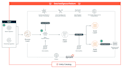
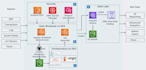
- Costruire pipeline ETL end-to-end (Estrazione, Trasformazione, Caricamento)
- Sviluppare PySpark / Spark jobs per l'elaborazione di grandi volumi di dati
- Progettare data lake su AWS S3
- Creare workflow usando Apache Airflow
- Implementare soluzioni Databricks per analisi e ML
- Ottimizzare le pipeline per prestazioni ed efficienza dei costi
- Integrare dati da API, database e file (CSV, JSON, Parquet)
Stack tecnologico:
- AWS: S3, Glue, IAM, CloudWatch
- Databricks
- Apache Spark / PySpark
- Apache Airflow
- Python / SQL
Perché scegliermi?
- Ho costruito pipeline che gestiscono dataset multi-terabyte
- Grande attenzione a ottimizzazione delle prestazioni
- Codice pulito, manutenibile e pronto per la produzione
- Comunicazione rapida e consegna affidabile
Esempi di casi d'uso:
- Pipeline di data warehouse
- Architettura di data lake
- Workflow batch e programmati
- Pulizia e trasformazione dei dati
- Pipeline di ingestione API su S3