Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD





Traduzione automatica.
Stanco dell'elaborazione manuale dei documenti? Lascia che l'AI lo faccia in pochi secondi.
Costruirò una pipeline personalizzata di OCR e Document Intelligence che estrae, elabora e analizza testo da PDF, file scannerizzati, fogli scritti a mano e immagini, fornendo output pulito, strutturato e pronto per la produzione.
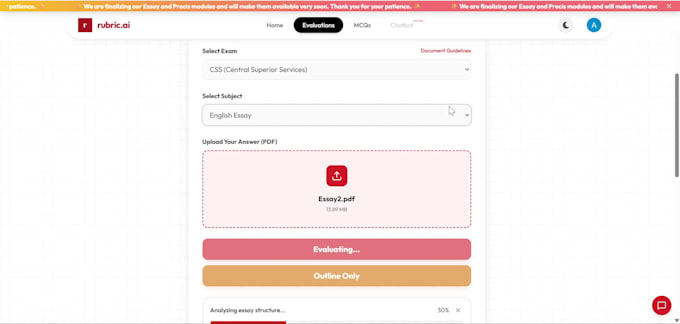
Ho creato e distribuito sistemi OCR reali come Rubric Ai inclusi una piattaforma di valutazione degli esami alimentata dall'AI e sistemi di pipeline automatizzata di elaborazione delle fatture con utenti reali, non progetti secondari.
Cosa costruisco: pipeline OCR per PDF, immagini e documenti scannerizzati Pre-elaborazione per input rumorosi, scritti a mano e di bassa qualità Analisi alimentata da LLM e estrazione intelligente del testo Annotazione automatica e motore di valutazione Output strutturato in JSON/CSV pronto per l'integrazione Backend FastAPI e integrazione database
Perfetto per: elaborazione di documenti legali, medici e finanziari Automazione di esami, valutazioni e votazioni Estrazione di dati da fatture, ricevute e contratti
Perché scegliere me: Sistemi OCR distribuiti reali, non solo tutorial Gestisce scrittura a mano, lingue miste e scansioni di scarsa qualità Codice pulito, codice sorgente completo incluso, consegna puntuale
Scrivimi e definiamo insieme il tuo progetto prima di ordinare.
Ai and Computer vision Solutions
Lingue
Traduzione automatica.
Traduzione automatica.
Puoi costruire un sistema personalizzato di valutazione o voto dei documenti?
Assolutamente. Ho creato motori di valutazione basati su rubriche e LLM che valutano e annotano i documenti sezione per sezione. Che si tratti di valutazione di esami, revisione di contratti o validazione di moduli, posso costruire una pipeline di valutazione intelligente su misura per i tuoi criteri.
Quali tipi di documenti può elaborare la tua pipeline OCR?
La mia pipeline OCR gestisce PDF, immagini scannerizzate, documenti fotografati e fogli scritti a mano. Funziona anche con scansioni di bassa qualità, contenuti multilingue e input rumorosi, con pre-elaborazione inclusa per garantire un'estrazione del testo pulita e accurata ogni volta.
Puoi integrare il sistema OCR con la mia applicazione o database esistente?
Sì. Costruisco backend REST FastAPI che si collegano direttamente alla tua applicazione esistente. Supporto MongoDB e PostgreSQL per lo storage strutturato dei dati e posso fornire output JSON o CSV compatibile con qualsiasi sistema downstream.
Cos'è l'intelligenza documentale e come si differenzia dal semplice OCR?
Il semplice OCR estrae solo testo. L'intelligenza documentale va oltre — usando LLM per analizzare, classificare, annotare e valutare il contenuto estratto rispetto a criteri definiti. È la differenza tra leggere un documento e comprenderlo davvero.
Fornite codice sorgente e documentazione?
Sì, ogni consegna include codice sorgente completo, commenti dettagliati e documentazione di setup, così il tuo team può mantenere e ampliare il sistema in modo indipendente senza dipendere da me.
Quanto tempo ci vuole per costruire una pipeline completa di intelligenza documentale?
Una pipeline di estrazione OCR di base richiede 3 giorni. Un sistema completo di intelligenza documentale con analisi LLM, motore di annotazione, API e integrazione database di solito richiede 7-10 giorni, a seconda della complessità. Contattami prima per avere una stima precisa del tuo progetto.