Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Progetti di sistemi e ML C Python SQL puntuali e ottimizzati
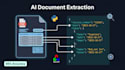
Se sei sommerso da PDF, fatture, moduli o immagini scansionate da cui bisogna estrarre dati, ti aiuto a creare sistemi AI pronti per la produzione che lo fanno automaticamente.
Sono un ingegnere di AI e computer vision con esperienza pratica nella creazione di pipeline di deep learning end-to-end, dai dati grezzi a una soluzione funzionante e deployabile che puoi usare davvero.
COSA COSTRUISCO
Elaborazione intelligente dei documenti (IDP)
Estrazione di dati strutturati da fatture, ricevute, contratti, moduli medici, documenti fiscali e qualsiasi formato PDF o immagine personalizzato.
Pipeline OCR personalizzate
Oltre all'OCR di base, costruisco sistemi AI che comprendono layout, tabelle, checkbox e scrittura a mano usando TesseractOCR, PaddleOCR e deep learning.
Visione artificiale & rilevamento oggetti
Modelli YOLO (v8/v11) personalizzati, classificazione immagini, segmentazione e tracciamento oggetti addestrati sul tuo dataset.
Sviluppo di modelli AI/ML
CNN, RNN, LSTM per classificazione, regressione, estrazione di testo NLP e previsioni di serie temporali.
Deployment di modelli & API
API REST tramite FastAPI o Flask, containerizzazione con Docker, deployment su cloud (AWS, GCP), integrazione con il tuo frontend.
STRUMENTI & STACK
Python, PyTorch, TensorFlow, OpenCV, YOLO, PaddleOCR, Tesseract

Linguaggio di programmazione:
Python
•
SQL
•
Colab
•
Java
•
MLflow
Framework:
Scikit-learn
•
Google ML Kit
•
keras
•
PyTorch
•
Panda
Traduzione automatica.
Devo fornire dati di training?
Dipende dal progetto. Per tipi di documenti comuni come fatture o ricevute, posso usare modelli pre-addestrati e adattarli al tuo formato. Per documenti altamente personalizzati o layout proprietari, un dataset di esempio di 50–200 esempi è ideale. Se non ne hai uno, posso guidarti su come raccoglierlo e
In quale formato verranno consegnati i dati estratti?
Di default consegno output strutturato in JSON o CSV. Se ne hai bisogno in un database, file Excel o integrato nel tuo sistema tramite API, si può organizzare — basta che me lo dica quando mi contatti.
Quanto sarà precisa l'estrazione?
La precisione dipende dalla qualità e complessità del documento. Per PDF digitali e puliti, si raggiunge generalmente il 95–99%. Per documenti scansionati o scritti a mano, il 85–95% è realistico. Testo che verifico sui tuoi documenti reali prima della consegna e includo un rapporto sulle prestazioni.
Puoi lavorare con documenti in altre lingue oltre all'inglese?
Sì. PaddleOCR supporta oltre 80 lingue e ho esperienza con pipeline multilingue. Ricordati di indicare la tua lingua quando mi contatti.
Possederò il codice?
Sì, al 100%. Tutto il codice sorgente, i pesi del modello e la documentazione sono tuoi. Non mantengo alcun diritto su ciò che costruisco per te.


