Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
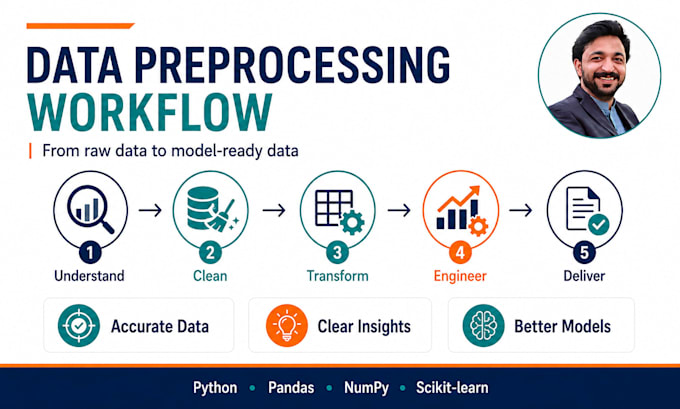
Hai a che fare con dati disordinati, incompleti, non strutturati o grezzi che devono essere preparati per machine learning, ricerca o analisi aziendale? Pulirò, preprocesserò, trasformerò e ingegnerò il tuo dataset in un formato pronto per l'AI usando Python e strumenti standard del settore.
I miei servizi includono:
Riceverai dati strutturati e puliti, codice Python riutilizzabile e documentazione chiara, a seconda del tuo pacchetto.
Contattami prima di ordinare così posso rivedere il tuo dataset, obiettivi, formato del file e requisiti del progetto.



Linguaggio di programmazione:
Python
•
SQL
•
Colab
•
NoSQL
•
MLflow
Framework:
Scikit-learn
•
SimpleCV
•
keras
•
PyTorch
•
Panda
Strumenti:
Quaderno jupyter
•
opencv
•
tensorflow
•
SimpleCV
•
CVAT
•
Colab
Traduzione automatica.
Che tipo di dataset puoi pulire e preprocessare?
Posso lavorare con CSV, Excel, tabelle strutturate, dataset di ricerca, dati aziendali, dati sanitari, dati di sondaggi, dati di previsione e dataset di machine learning.
Cosa farai nel preprocessing dei dati?
Posso gestire valori mancanti, duplicati, outlier, record non validi, formattazione incoerente, codifica, scaling, normalizzazione, standardizzazione e trasformazione dei dati.
Fornisci feature engineering?
Sì. Posso creare nuove feature significative, selezionare quelle importanti, ridurre le feature non necessarie e preparare il dataset per modelli di machine learning.
Riceverò il codice sorgente?
Sì, a seconda del pacchetto. Posso fornire codice Python pulito e riutilizzabile usando strumenti come Pandas, NumPy, Scikit-learn e Jupyter Notebook.
Puoi eseguire analisi esplorativa dei dati?
Sì. Posso fornire EDA comprensiva di statistiche riassuntive, analisi di distribuzione, analisi di correlazione, visualizzazioni e approfondimenti chiave dal tuo dataset.
Puoi preparare i dati per modelli di machine learning?
Sì. Posso preparare un dataset pronto per l'AI adatto a classificazione, regressione, clustering, previsioni o progetti di deep learning.
Lavori su dataset di ricerca o tesi?
Sì. Posso aiutare con la preparazione di dataset per tesi, pubblicazioni, ambito accademico, sanità, EEG/BCI e ricerca di livello avanzato.
Q8: Di cosa hai bisogno da me prima di iniziare?
Condividi il tuo dataset, obiettivo del progetto, colonna target se disponibile, formato di output richiesto e eventuali requisiti specifici di preprocessing o feature engineering.
Puoi costruire un modello di machine learning in questo servizio?
Questo servizio si concentra principalmente su preprocessing dei dati e feature engineering. Se hai bisogno di sviluppo di modelli, posso offrirlo come servizio extra o tramite un servizio ML separato.
Q10: Devo contattarti prima di effettuare un ordine?
Sì, contattami prima così posso rivedere il tuo dataset, capire le tue esigenze e consigliarti il miglior pacchetto.