Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Freelancer esperto dedicato a contenuti di qualità
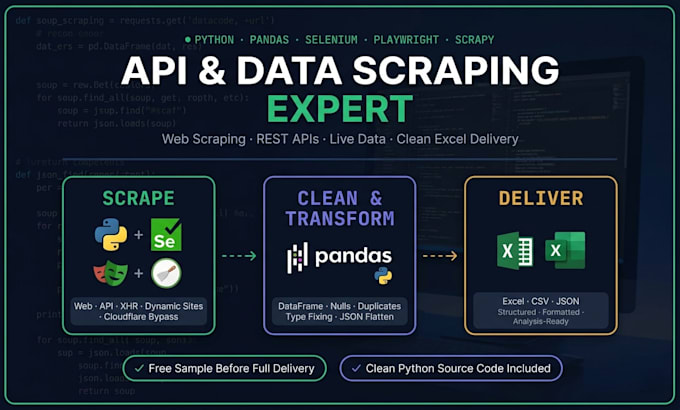
Scraperò siti web dinamici e endpoint API.
Hai bisogno di dati da qualsiasi sito web, API nascosta o feed live strutturato, pulito e pronto all'uso? Sei nel posto giusto.
Gestisco sia web scraping dinamico che estrazione di endpoint API da pagine renderizzate con JavaScript fino a API XHR/Fetch reverse-engineerate, e consegno tutto attraverso un completo pipeline di pulizia e formattazione con Pandas.
COSA OTTIENI:
Scraping di siti web dinamici
Scoperta e reverse engineering di endpoint API (XHR/Fetch)
Scraping di token API REST, intestazioni di autenticazione, gestione sessione
Bypass di Cloudflare, Turnstile e anti-bot
Dati in tempo reale: punteggi sportivi, crypto, prezzi, annunci
JSON annidato appiattito in fogli strutturati
Output in Excel / CSV / JSON
️ STACK:
Python · Pandas · Selenium · Playwright · Scrapy · Requests · BeautifulSoup · openpyxl
PERCHÉ SCEGLIERE ME :
Scraping web e estrazione API con un solo venditore, copertura completa
Campione gratuito prima della consegna completa
Script Python riutilizzabile incluso con ogni ordine
File puliti, tipizzati e formattati, niente dump grezzi
Specialista in Turnstile e Cloudflare
Scrivimi prima per verifica di fattibilità, senza impegno.


 (1)_kv3che.jpg)
 (1)_h3ydiz.jpg)
Tecnologia:
Python
•
Excel
•
selenium
•
Beautiful soup
•
Pandas
Tipo di informazioni:
Siti web
Tecnica:
Automatizzato
Traduzione automatica.
Q1: Qual è la differenza tra web scraping e API scraping?
Il web scraping estrae dati direttamente dall'HTML di un sito — utile per pagine senza API pubblica. L'API scraping intercetta le chiamate backend nascoste (XHR/Fetch) per ottenere dati più puliti, veloci e affidabili. Faccio entrambi — quello che ti dà i migliori risultati per il tuo sito specifico.
Q2: Puoi scrapeare siti web renderizzati con JavaScript o dinamici?
Sì. Uso Selenium e Playwright per renderizzare completamente le pagine JavaScript, gestire scroll infinito, caricamenti lazy e contenuti AJAX prima di estrarre i dati — così niente viene perso.
Q3: Puoi bypassare la protezione di Cloudflare o Turnstile?
Sì. Ho esperienza diretta nel catturare token di Cloudflare Turnstile, inclusi challenge triggerati dallo scroll e basati sull'user-agent — uno dei sistemi di protezione bot più complessi attualmente in uso. Contattami con il sito di destinazione per una verifica di fattibilità gratuita.
Q4: Cosa significa "pulizia e formattazione dei dati"?
Prima della consegna, ogni dataset passa attraverso una pipeline completa di Pandas: valori nulli gestiti, duplicati rimossi, tipi di dato corretti, nomi di colonne standardizzati, JSON annidato appiattito e formattato in Excel con intestazioni e larghezze di colonna adeguate. Ricevi un file finito, professionale — niente dump grezzi.
Q5: Riceverò lo script Python?
Sì — ogni ordine include codice sorgente Python pulito, commentato e riutilizzabile, così puoi ri-eseguire lo scraper in qualsiasi momento senza dover riassumere tutto da capo.
Q6: Quali formati di output consegni?
Di default, Excel (.xlsx), CSV e JSON. Su richiesta, consegna anche su Google Sheets. Basta indicarlo prima di ordinare.
Q7: È legale fare web scraping?
Lavoro solo con dati pubblicamente accessibili e non effettuo scraping di siti che vietano esplicitamente nel loro Termini di servizio. Non estraggo dati privati degli utenti né bypasso paywall. Contattami con l'URL di destinazione prima di ordinare, così posso confermare fattibilità e conformità.
Q8: Come posso iniziare?
Contattami prima di fare un ordine. Condividi URL di destinazione, campi dati necessari e volume approssimativo. Ti confermerò fattibilità, tempi e eventuali sfide tecniche — completamente gratuito, senza impegno.