Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD



Traduzione automatica.
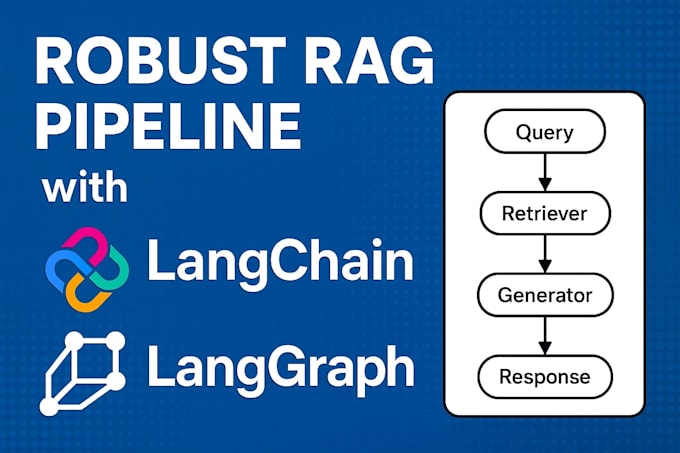
Progetto e realizzo pipeline Retrieval-Augmented Generation (RAG) robuste che forniscono risposte precise e consapevoli del contesto dai tuoi dati.
Niente allucinazioni. Niente script fragili. Solo architetture di livello produzione pulite, modulari e completamente documentate.
️ Cosa ottieni
Perché lavorare con me
Stack tecnologico: Python · LangChain · LlamaIndex · Hugging Face · FAISS · Chroma · API OpenAI · Streamlit · FastAPI
Discutiamo delle tue fonti di dati e della stack di deployment desiderata
Machine Learning, Deep learning, Gen AI and Agentic AI
Lingue
Traduzione automatica.
Traduzione automatica.
Posso usare i miei dati (PDF, Notion, Google Drive)?
Assolutamente sì. Posso configurare connettori per le tue fonti di dati locali o cloud.
Riceverò il codice sorgente completo?
es. Tutti i file di codice e di ambiente sono inclusi e documentati.
Puoi integrare con la mia app o API esistenti?
Sì — posso avvolgere la pipeline RAG con endpoint FastAPI o integrarla nel tuo frontend.