Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Ci occupiamo di
Servizi principali
Processo
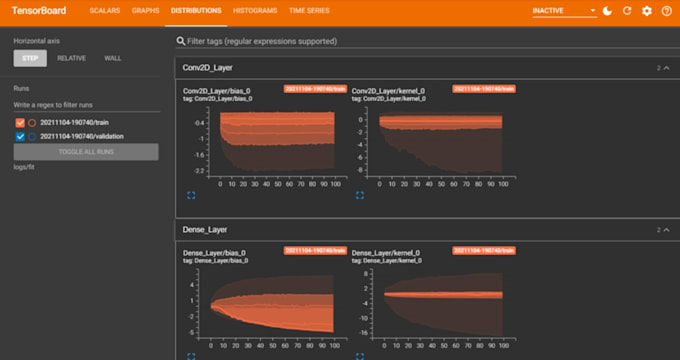
Stack
PyTorch, TensorFlow, HF, scikit-learn, Optuna, MLflow, ONNX/TensorRT, Docker/FastAPI
Proprietà
Tu possiedi codice e pesi. I costi GPU cloud sono addebitati alle tariffe del provider. NDA/white-label disponibile.
Per iniziare

Linguaggio di programmazione:
Python
•
MATLAB
•
Colab
•
MLflow
•
Julia
Framework:
Scikit-learn
•
DeepPy
•
keras
•
PyTorch
•
Panda
•
tensorflow
Traduzione automatica.
Firmerai un NDA?
Sì. Sono a mio agio con NDA e/o una clausola di riservatezza reciproca. Anche il lavoro in white-label va bene.
Come proteggete i miei dati?
Accesso con privilegi minimi, repo privati, archiviazione criptata (quando si usa il cloud) e nessuna condivisione con terze parti. Elimino dataset e artefatti su richiesta o 14 giorni dopo la consegna.
Chi possiede il modello e il codice?
Tu. Trasferimento completo dei pesi addestrati, del codice sorgente e della documentazione. Nota: i modelli di base/lib open-source mantengono le loro licenze originali.
Quali sono i tempi di consegna tipici?
Base: 7 giorni, Standard: 14 giorni, Premium: 28 giorni. Opzioni extra-veloci sono disponibili in Extras.
Cosa può influenzare i tempi?
Dimensione/qualità dei dati, etichettatura, numero di prove HPO, requisiti di conformità e complessità del deployment (cloud, scaling, sicurezza).
Puoi deployare il modello per uso in produzione?
Sì. Il piano Premium include il deployment su cloud; lo Standard consegna uno scheletro di API. Posso fornire un REST API Dockerizzato con controlli di salute e documentazione.
Quali stack supporti?
PyTorch/TensorFlow, Hugging Face, ONNX/TensorRT, FastAPI + Docker. Mi integro con AWS/GCP/Azure, Vercel/DO o il tuo on-premise.
Ottengo esportazioni per mobile/edge?
Sì, esportazione del modello in ONNX; TFLite/Core ML su richiesta, soggetto alla compatibilità del modello.
Cosa include la documentazione?
Note di setup, comandi di esecuzione, specifiche dell'endpoint, rapporto di valutazione e una scheda del modello che copre metriche, dati e limiti.
Fornite manutenzione?
Sì. È disponibile un mantenimento mensile opzionale (correzione bug, piccoli aggiornamenti) come Extra o piano personalizzato.