Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD



Traduzione automatica.
Le wrapper generici di ChatGPT falliscono su larga scala. Hai bisogno di un integrazione AI personalizzata ancorata ai tuoi dati privati.
Come ingegnere AI Full Stack, progetto infrastrutture avanzate di Python AI. Supero gli script di base per costruire ecosistemi complessi di LLM Integration. Che tu abbia bisogno di un backend SaaS o di una pipeline RAG su misura per la ricerca semantica, sviluppo agent AI personalizzati per ragionamenti a più passaggi.
Deliverables architetturali:
Vantaggi dell'ingegneria:
Scrivimi le tue esigenze. Progettiamo insieme il tuo sistema AI oggi.
Full Stack AI Engineer
Lingue
Traduzione automatica.
Traduzione automatica.
Come garantisci che i dati della mia azienda rimangano sicuri durante l'integrazione AI?
Progetto backend Python sicuri con vector DB isolati (Milvus/PostgreSQL). I dati vengono elaborati tramite API di livello enterprise (AWS Bedrock, Anthropic) con politiche di zero retention, assicurando che i tuoi dati proprietari non vengano mai usati per addestrare modelli pubblici.
Puoi impedire all'agente AI di hallucinate o inventare fatti?
Sì. Progetto pipeline RAG avanzate usando ricerca semantica e vector database. Questo limita il LLM a sintetizzare risposte solo dai documenti aziendali inseriti, eliminando completamente hallucination e garantendo output fattuali.
Come colleghi il backend AI personalizzato al mio software esistente?
Come ingegnere Full Stack, costruisco endpoint FastAPI Python robusti che collegano senza problemi i tuoi nuovi agenti AI a qualsiasi frontend (Next.js, React) o piattaforma SaaS esistente. Ricevi API completamente documentate e pronte per la produzione per un deployment immediato.
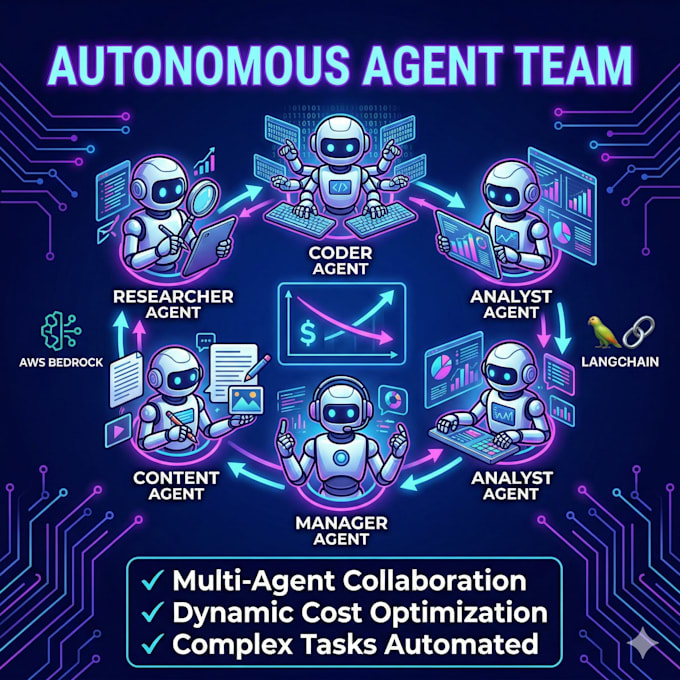
Come gestiamo i costi API quando scalano i sistemi multi-agente?
Distribuisco LiteLLM Server e OpenRouter all’interno della tua architettura. Questo permette di fare routing dinamico dei modelli—passando automaticamente tra GPT-4, Claude o Llama in base alla complessità del task—massimizzando le prestazioni di inferenza e riducendo drasticamente i costi API.
Possiedo il codice sorgente e l'infrastruttura AI dopo la consegna?
Assolutamente sì. Consegnò codice Python completamente documentato e l'architettura del sistema. Che sia ospitato su AWS Bedrock o su server cloud personalizzati, mantieni il 100% della proprietà e del controllo sulla tua pipeline AI proprietaria, agenti e endpoint di integrazione.