Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Ingegnere di big data
Livello 2
Ha soddisfatto criteri di prestazioni elevate e ha una comprovata esperienza nel soddisfare le aspettative dei clienti.
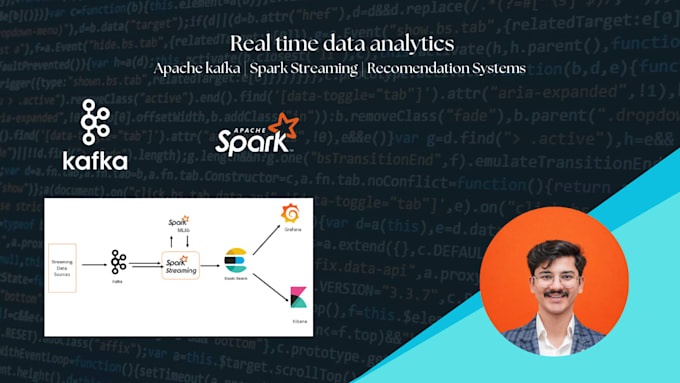
Le applicazioni moderne generano enormi flussi di dati in tempo reale da siti web, app mobili, dispositivi IoT e piattaforme cloud. Elaborare questi dati in modo efficiente richiede architetture di streaming scalabili e pipeline di dati affidabili.
Sono un Data Engineer specializzato in sistemi big data e elaborazione in tempo reale, e ti aiuterò a progettare e implementare pipeline di streaming ad alte prestazioni usando tecnologie come Apache Kafka e Apache Spark.
Ho esperienza nella costruzione di sistemi di dati distribuiti e pipeline di analisi su larga scala, tra cui un sistema di raccomandazione musicale in tempo reale che ha elaborato oltre 100GB di dati in streaming usando Hadoop e Spark, e pipeline ETL in tempo reale con data warehousing per analisi aziendali.
Tecnologie
Esempi di casi d'uso
Mi concentro sulla costruzione di pipeline di streaming scalabili, affidabili e pronte per la produzione che trasformano dati live in insight utili.
Contattami prima di effettuare un ordine per discutere le tue esigenze.