Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Data Science e Intelligenza Artificiale
Cerchi qualcosa di più di uno script NLP di base?
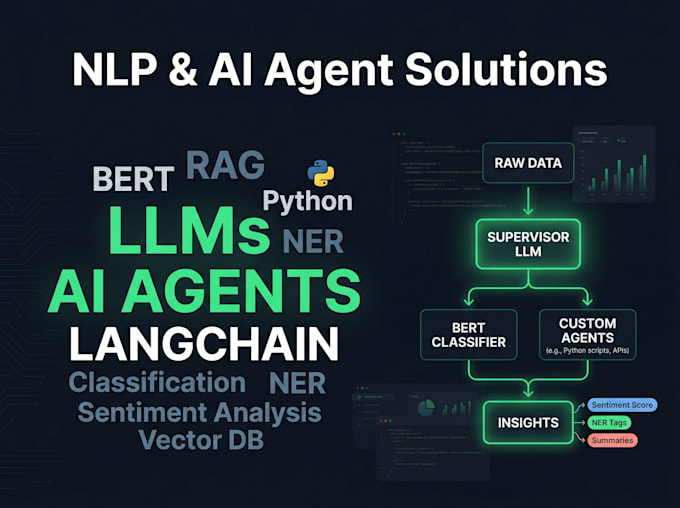
Costruisco sistemi di testo intelligenti end-to-end, dai pipeline classici NLP a modelli BERT ottimizzati e agent AI pronti per la produzione, alimentati da LangGraph e LangChain. Che tu abbia bisogno di un classificatore di sentiment, di un chatbot specifico per un dominio o di un sistema LLM multi-agent completo, consegno soluzioni pulite, documentate e facilmente deployabili.
Ciò che offro:
1. NLP & Text Analytics
Preprocessing del testo: tokenizzazione, rimozione delle stopword, lemmatizzazione (spaCy / NLTK)
Classificazione del testo & analisi del sentiment (Naive Bayes, SVM, regressione logistica)
Named Entity Recognition (NER), estrazione di parole chiave e keyphrase
TF-IDF, analisi N-gram, frequenza delle parole, reti di co-occorrenza
Topic Modeling LDA, NMF, BERTopic
Riassunto del testo & similarità semantica
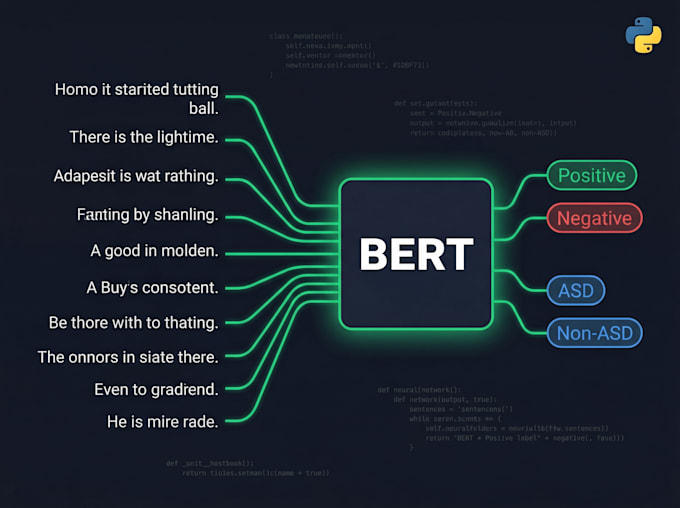
2. BERT & Fine-tuning Transformer
Ottimizzazione di BERT, RoBERTa, DistilBERT, AraBERT sul tuo dataset personalizzato
Classificazione di sequenze, classificazione di token, risposte a domande
Curve di training, report di valutazione (accuratezza, F1, matrice di confusione)
Salvataggio & esportazione dei pesi del modello (formato HuggingFace, .pth, .zip)
3. Agent AI & soluzioni LLM
Orchestrazione multi-agent usando LangGraph, dominio specifico



Linguaggio di programmazione:
Python
•
MATLAB
•
SQL
•
Colab
Framework:
Scikit-learn
•
PyTorch
•
Panda
API:
Altro
Strumenti:
Quaderno jupyter
•
opencv
•
tensorflow
•
Excel
•
Colab
Traduzione automatica.
Q1: Con che tipo di dati testuali puoi lavorare?
Qualsiasi dominio — testo medico/clinico, recensioni clienti, post sui social media, commenti YouTube, documenti legali, articoli accademici, rapporti finanziari, risposte a sondaggi. Se hai testo, posso costruire qualcosa con esso.
Q2: Ho bisogno di un dataset etichettato per la classificazione?
Per compiti supervisionati (classificazione, sentiment) — sì, sono necessari dati etichettati. Per compiti non supervisionati (topic modeling, clustering, estrazione di parole chiave) — va bene il testo grezzo. Posso anche consigliarti sulla strategia di etichettatura se parti da zero.
Q3: Puoi costruire un sistema RAG per i miei documenti o la mia knowledge base?
Sì — questo rientra nel pacchetto Premium. Configurerò un vettore di memorizzazione (FAISS o Chroma), lo collegherò ai tuoi documenti e costruirò una pipeline di retrieval con LangChain in modo che il tuo LLM risponda alle domande esclusivamente dai tuoi dati.
Q4: Con quali LLM lavori?
OpenAI GPT-3.5 / GPT-4, Groq (LLaMA 3, Mixtral), Google Gemini, Mistral. Posso lavorare con quello che preferisci o a cui hai già accesso tramite API. Posso anche usare modelli open-source locali tramite Ollama se vuoi zero costi API.
Q5: Potrò eseguire e modificare il codice da solo?
Assolutamente sì. Tutti i deliverable sono notebook Jupyter/Colab puliti e commentati. Scrivo codice per gli esseri umani, non solo per le macchine. Capirai ogni passaggio e sono felice di spiegarti tutto dopo la consegna.
Q6: Puoi deployare il modello o l'agente come API o web app?
Il deployment di base (endpoint FastAPI o app Streamlit) può essere aggiunto come extra. Per un deployment completo su cloud (AWS, GCP, Hugging Face Spaces), contattami prima di ordinare per un preventivo personalizzato.