Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Ingegnere capo dei dati
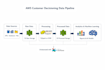
Sono un Senior Data Engineer con oltre 6 anni di esperienza nella progettazione di pipeline di dati scalabili e piattaforme di dati cloud. Mi specializzo nella creazione di workflow ETL affidabili, trasformando dati grezzi in set di dati strutturati e abilitando sistemi di dati pronti per l'analisi.
Posso aiutarti con:
-Sviluppo di pipeline ETL usando Python, SQL e Pyspark
-Ingestione di dati da API, file e database
-Trasformazione e ottimizzazione dei dati
-Pipeline di dati cloud usando AWS (S3, EMR, Redshift, Glue, Kinesis, Athena)
-Architettura Lakehouse (strati Bronze, Silver, Gold)
-Integrazione e ottimizzazione delle performance del data warehouse
Mi concentro sulla costruzione di pipeline di dati efficienti, scalabili e pronte per la produzione che supportano analisi, report e workflow di machine learning.
Se hai bisogno di aiuto per progettare o migliorare la tua pipeline di dati o piattaforma di dati, sentiti libero di contattarmi prima di effettuare un ordine.

Warehouse Platform:
Snowflake
•
redshift
•
PostgreSQL / Greenplum
Tipo di progetto:
New Build
