Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Facciamo in modo che il machine learning lavori per i tuoi obiettivi!
Chi sono
Ciao! Sono Sivanandham, uno Specialista in Machine Learning con un background comprovato in previsioni finanziarie, predizione del mercato azionario e automazione basata sui dati. Con oltre 2 anni di esperienza pratica in Intelligenza Artificiale, Machine Learning, Data Analysis, Data Science e sistemi di AI.
Ho realizzato più di 25 progetti ML nel mondo reale che hanno effettivamente risolto problemi di business, non solo demo accademiche.
Servizi che offro:
Sviluppo di modelli ML: Classificazione, Regressione
Fasi del pipeline: Ingestione dati, Pulizia e Preprocessing dei dati, Feature engineering, Addestramento del modello, Tuning degli iperparametri, Validazione e Predizione
Training e valutazione del modello: Accuratezza, F1-Score, ROC-AUC
Ottimizzazione del modello: Metriche di valutazione, GridSearchCV
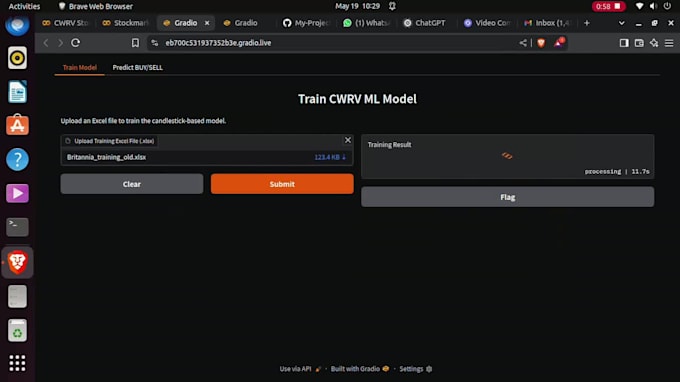
Deployment del modello: App basate su Gradio, deployment locale
Strumenti e tecnologie:
Lingue e librerie: Python, Pandas, NumPy, Matplotlib, Seaborn, Gradio, Excel, Scikit learn
Algoritmi ML: Alberi decisionali, Support Vector Machine (SVM), Regressione logistica/lineare, Gradient Boosting, Cross-Validation, Grid Search
Controllo versione: GitHub
Consiglio: Prima di effettuare un ordine, inviami un messaggio con il tuo dataset, obiettivi e aspettative così posso fornirti il piano e i tempi giusti per te




Linguaggio di programmazione:
Python
•
Colab
Framework:
Scikit-learn
•
PyTorch
•
Panda
API:
Google Cloud Vision API
Strumenti:
Quaderno jupyter
•
opencv
•
Excel
•
MLflow
•
Colab
Traduzione automatica.
Puoi lavorare con il mio dataset grezzo o deve essere già pulito?
Sì, posso lavorare con dati grezzi. Offro pulizia completa dei dati (ETL), preprocessing e trasformazioni per rendere il tuo dataset pronto per ML — inclusa la gestione di valori mancanti, outlier e problemi di formattazione
Quali risultati riceverò?
Riceverai codice Python (pulito e commentato bene), visualizzazioni delle performance (matrice di confusione, curva ROC, importanza delle feature), spiegazioni del modello e file pronti per il deploy
Come garantisci che il modello funzioni bene?
Utilizzo tecniche comprovate come cross-validation, split train-test, analisi bias-variance e tuning degli iperparametri (GridSearchCV) per creare modelli ottimizzati e robusti.
Come scelgo tra i pacchetti Basic, Standard e Advanced?
● Basic è ottimo per casi d'uso semplici o principianti. ● Standard include preprocessing completo, gestione degli squilibri e tuning — ideale per piccole imprese. ● Advanced offre modelli pronti per la produzione, confronto tra più algoritmi e UI perfetta per professionisti e progetti di ricerca.
I miei dati rimarranno privati?
Assolutamente. I tuoi dati sono trattati come confidenziali e non verranno mai condivisi o riutilizzati.
Come posso essere sicuro che il tuo servizio sia affidabile?
Con oltre 25 progetti ML reali, formazione avanzata (certificazione AI di 6 mesi da Novi Tech) e risultati comprovati (ad esempio, crescita del 2166% usando insights ML), fornisco modelli strutturati, spiegabili e di impatto, personalizzati per i tuoi obiettivi.
Puoi fornire documentazione o spiegazioni in stile notebook?
Sì. Posso consegnare il progetto in formato Jupyter Notebook o Google Colab con spiegazioni passo passo, commenti e output visivi per una migliore comprensione e riutilizzo.
Quale dimensione di dataset puoi gestire?
Posso lavorare con dataset di piccole o medie dimensioni in modo efficiente, con offerte personalizzate per garantire prestazioni ottimali usando tecniche di gestione della memoria efficaci.
Quali servizi specifici di data science offri?
Offro una gamma di servizi tra cui pulizia e preprocessing dei dati, analisi esplorativa, modellazione predittiva, tuning fine, sviluppo di algoritmi di machine learning, visualizzazione dei dati e insights azionabili.
Come garantite la riservatezza e la sicurezza dei miei dati?
I tuoi dati sono trattati con la massima riservatezza. Tutti i dati sensibili vengono processati in ambienti sicuri e non verranno caricati online o processati tramite piattaforme online: i tuoi dati sono accessibili solo a te e al Jupyter Notebook in esecuzione sul mio laptop.