Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
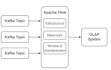
Data Engineer, ETL, API e automazione BI
Ciò che posso fare:
Connessione completa alle fonti di dati (multi-sorgente / pipeline complesse)
Integrazione API + integrazione sistemi esterni
Funzionalità avanzate di Flink (checkpointing, gestione dello stato, windowing, join)
Ottimizzazione del sistema e tuning delle prestazioni
Guida alla progettazione dell'architettura
Formattazione e pulizia
Include codice sorgente completo + documentazione
"Un ingegnere dei dati assolutamente brillante. Ha configurato perfettamente il nostro pipeline di streaming Kafka-to-Flink per il nostro MVP. Il codice era pulito, ben documentato e consegnato puntualmente."
-- David L., Tech Lead
"Avevamo problemi con la gestione dello stato e il windowing nel nostro processo ETL in tempo reale. Non solo ha risolto i nostri bug, ma ha ottimizzato l'intera architettura di Flink. Altamente raccomandato per flussi di dati complessi!"
-- Alex R., Data Architect
"Veloce, professionale e con una profonda esperienza in Apache Flink. Ha integrato senza problemi più API esterne nel nostro flusso di dati e ha ottimizzato le prestazioni perfettamente per la produzione. Lo riassumerò sicuramente."
-- Sarah M., fondatrice di startup



Expertise:
Big data
•
Flusso di dati
•
etl
Tecnologia:
Apache Kafka
•
Apache Spark
•
Java
•
Python
•
Scala
•
Altro


