Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD




Traduzione automatica.
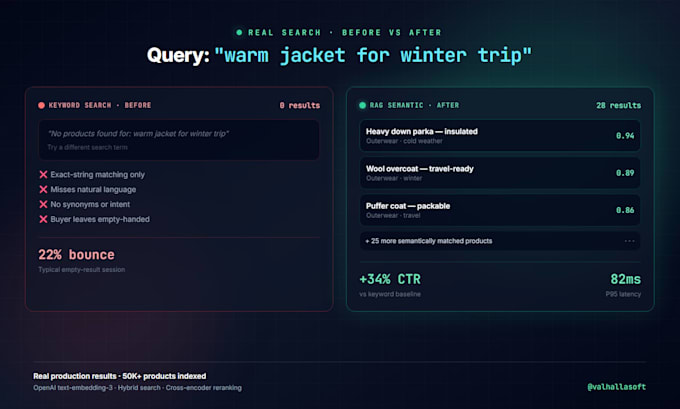
Smetti di perdere vendite a causa di una ricerca scadente.
Se la ricerca del tuo ecommerce non restituisce risultati quando i clienti digitano query naturali invece di SKU esatti, stai lasciando soldi sul tavolo. Implemento sistemi di ricerca RAG e semantica di livello produttivo che comprendono l'intento, non solo le parole chiave.
Risultato reale: attualmente sto guidando la migrazione della ricerca AI per uno dei più grandi rivenditori dell'America Latina (oltre 200 negozi, più di 1 milione di utenti al giorno, oltre 50.000 prodotti), sostituendo l'API di Google Search con un sistema basato su RAG che si prevede farà risparmiare 500.000 dollari all'anno.
Ciò che ottieni:
Stack: Python (FastAPI), OpenAI / sentence-transformers, AWS, Docker, Kubernetes.
Perché me: oltre 10 anni di esperienza nella creazione di backend di livello enterprise. Senior Platform Engineer con responsabilità di architettura cross-team. Consegno deliverable testati e documentati, così il tuo team può gestire il sistema dopo la consegna.
Scrivimi con il tuo stack, la dimensione del catalogo e cosa non funziona nella tua ricerca attuale. Rispondo entro 1 ora con i prossimi passi concreti.
Senior RAG and AI Search Engineer for Backend at Scale
Lingue
Traduzione automatica.
Traduzione automatica.
Quale database vettoriale dovrei usare?
Dipende da scala, costi e vincoli operativi. Ti aiuto a scegliere tra Pinecone (gestito), Weaviate (self-hosted), Qdrant (open source) e pgvector (senza nuova infrastruttura). Il pacchetto di Revisione dell'architettura include questa decisione.
Quanto costa l'API di embedding di OpenAI?
Per 50K prodotti con OpenAI text-embedding-3-small, i costi iniziali di indicizzazione sono circa 1-2 USD. L'embedding delle query costa circa 0.00002 USD per ricerca. Includo proiezioni di costi nei pacchetti Standard e Premium.
Puoi integrarti con il mio backend di ricerca esistente?
Sì. La ricerca ibrida che combina il tuo backend di parole chiave con vettori semantici di solito supera la pura semantica. Mi integro con Elasticsearch, Algolia, Typesense, OpenSearch e Meilisearch.