Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Facciamo il tuo progetto CONCLUSO
Benvenuto ;
Sono Big Data Engineer con 5 anni di esperienza
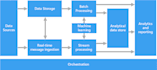
Posso aiutarti a sviluppare il tuo progetto big data, includendo data ingestion (usando Apache Kafka), storage dei dati (in Hadoop o Amazon S3 o nel tuo Data Lake remoto), elaborazione dei dati in batch o stream (in tempo reale) con pySpark o pyFlink, analisi dei dati (usando machine learning e MLlib per big data), e anche analisi e visualizzazione in dashboard
Ecco cosa includono i miei servizi:
Rimborso del 100% se il lavoro non viene eseguito come richiesto.
NOTA:
Sono accettati anche ordini personalizzati. Per favore, inviami un messaggio prima di effettuare l'ordine.
Grazie per essere qui. Contattami ora per iniziare.
Cordiali,


Expertise:
Automazioni
•
Big data
•
etl
•
Trasformazione
•
SQL
•
NoSQL
| (1) | ||
| (0) | ||
| (0) | ||
| (0) | ||
| (0) |
anushabandari
Cliente abituale

Stati Uniti
Good and very knowledgeable
| (1) | ||
| (0) | ||
| (0) | ||
| (0) | ||
| (0) |
anushabandari
Cliente abituale
Stati Uniti
Good and very knowledgeable


