Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Data Engineer specializzato in ETL Pipelines, Databricks, Azure e Power BI
Ciao, sono un consulente di Data Engineering con oltre 5 anni di esperienza nella creazione di pipeline di dati in produzione su Databricks.
Ho progettato carichi di lavoro reali su Databricks in produzione, tra cui una Customer Data Platform che elabora grandi dataset con PySpark, Delta Live Tables e architettura medallion. Lavoro quotidianamente su Databricks, non solo come parola di moda.
Cosa costruirò per te:
Perché lavorare con me:
Stack tecnologico:
Prima di ordinare:
Contattami con tutte le tue esigenze complete.

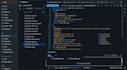
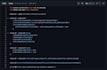
Destination Platform:
Databricks Lakehouse
Strumenti e piattaforme:
Altro


