Sfoglia categorie
Esplora
Fiverr Pro
Italiano
$
USD
Sviluppatore di pipeline bioinformatiche
Hai dati di espressione genica etichettati e hai bisogno di
un classificatore di machine learning per prevedere i sottotipi di cancro
o gli esiti dei pazienti?
Costruirò una pipeline completa di classificazione ML
su misura per il tuo dataset genomico.
COSA OTTIENI:
- Preprocessing e normalizzazione dei dati
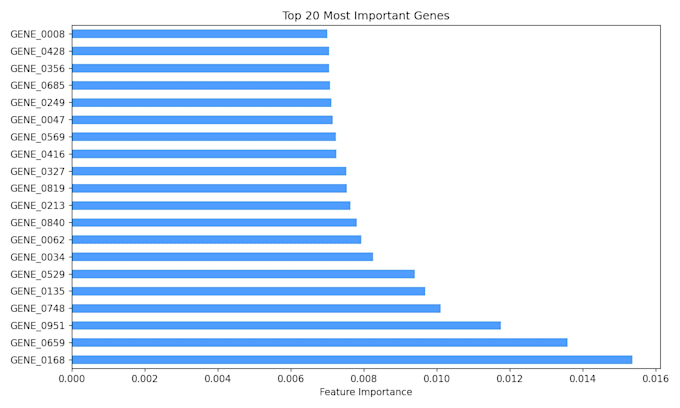
- Selezione delle caratteristiche per identificare i geni più informativi
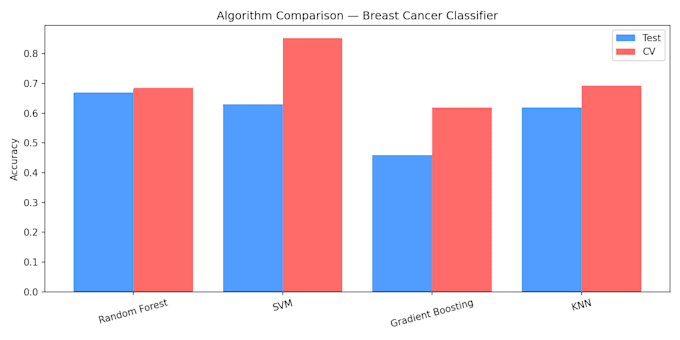
- Confronto tra più algoritmi (Random Forest, SVM,
Gradient Boosting, KNN)
- Valutazione dell'accuratezza con cross-validation
- Matrice di confusione e rapporto di classificazione
- Visualizzazione dell'importanza delle caratteristiche
- Modello pronto per la produzione salvato
LA MIA ESPERIENZA:
Ho costruito un classificatore di sottotipi di cancro al seno sui dati di espressione genica
raggiungendo un'accuratezza del 85,2% con cross-validation
usando SVM. Ho classificato 4 sottotipi:
LuminalA, LuminalB, HER2, TriploNegativo.
Pipeline completa su GitHub.
COSA MI SERVE DA TE:
- Matrice di espressione genica (campioni x geni)
- Etichette di sottotipo o esito per ogni campione
- Numero di classi da prevedere
- Eventuali geni o percorsi importanti noti
STRUMENTI: Python, scikit-learn, Pandas, numpy,
matplotlib, seaborn, joblib, Linux, Git



Expertise:
Classificazione
•
clustering
•
Analisi predittiva
Linguaggio di programmazione:
Python
•
R
Framework:
Scikit-learn
•
Panda
API:
Altro
Strumenti:
Quaderno jupyter
•
RStudio